Run and monitor production systems on Pipedream


Our users run over a million apps on Pipedream: everything from internal tools to production workflows. We run production Pipedream systems on the platform itself: our email trigger, customer communication, error notifications, and more.
And like every app, things break. Third-party APIs go down, you accidentally ship a bug to a workflow, your app receives input it didn't expect, and more. Failure is inevitable. So you need timely alerts, detailed logs, and automation of failure recovery.
We reflected on the work we've done internally, and our conversations with customers, and wanted to share practical advice for how to run and monitor critical apps on Pipedream.
Design your workflow
Workflows are apps, built in a series of linear steps. When we first design workflows, we consider two things:
- When does the workflow run?
- What do we do when that event happens?
In Pipedream, these map to steps:
- The trigger step — Triggers define the type of event that runs your workflow. For example, HTTP triggers expose a URL where you can send any HTTP requests. Pipedream will run your workflow on each request. The Scheduler trigger runs your workflow on a schedule. Workflows can have more than one trigger.
- Actions and code — Actions and code steps drive the logic of your workflow. Anytime your workflow runs, Pipedream executes each step of your workflow in order. Actions are pre-built code steps that let you connect to any API without writing code. When you need more control than the default actions provide, code steps let you write any custom Node.js, Python, Go or Bash code.
Once you design your workflow, you should see what built-in triggers and actions you can use on Pipedream. We've developed and QA'd thousands of these integrations, so you don't have to write code to use them — just fill in the required argument and go.
Pick the right trigger
Trigger steps, especially, can handle a lot of logic for you. When an API supports webhooks (like Google or GitHub), Pipedream will automatically subscribe to events from the source service. When it doesn't, we poll API endpoints for new events on a schedule, triggering the workflow when they occur.
We also validate webhook signatures to authorize incoming requests, and dedupe duplicate events so your workflow doesn't accidentally get triggered twice.

You can see the code for all of these integrations on our public GitHub repo, submit a pull request to fix an issue, or talk to our team if you need something we don't have yet. You can even build your own integrations when you need custom logic.
Understand the fault tolerance of your event source
The Pipedream service itself, and your individual apps, will inevitably encounter errors. Many apps will retry webhook requests on errors. Stripe, for instance, provides detailed docs on exactly how it handles specific types of errors:
In live mode, Stripe attempts to deliver your webhooks for up to three days with an exponential back off. In the Events section of the Dashboard, you can view when the next retry will occur.
Find your app's docs or reach out to their support team to ask if they can give you the same level of insight. Document this in your incident playbooks so you understand this behavior when things fail.
If you're sending your own requests to Pipedream — from your app or from your users' browsers — you should handle back off and retry in the same way. Where possible, retry all HTTP 5XX errors, and implement your own alerting / logging for these errors. If you're seeing persistent unexpected errors, check Pipedream's status page or reach out to our team.
Sanitize input: Add a filter step
Most trigger steps run on a broad set of events. For example, GitHub sends HTTP requests on all labeled and unlabeled events — when labels are added to issues and pull requests — but they don't let you filter on events for specific labels. You get all or nothing.
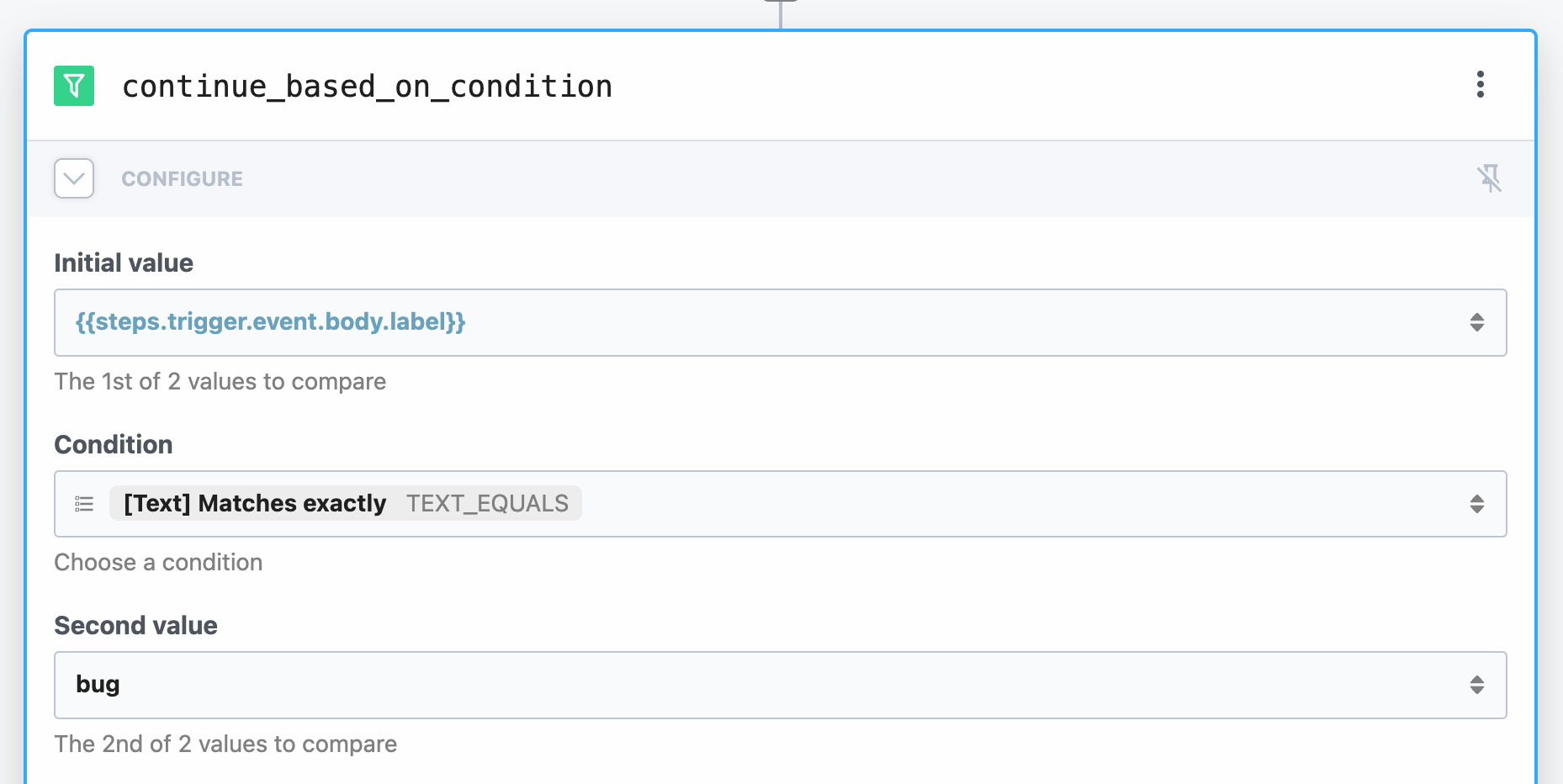
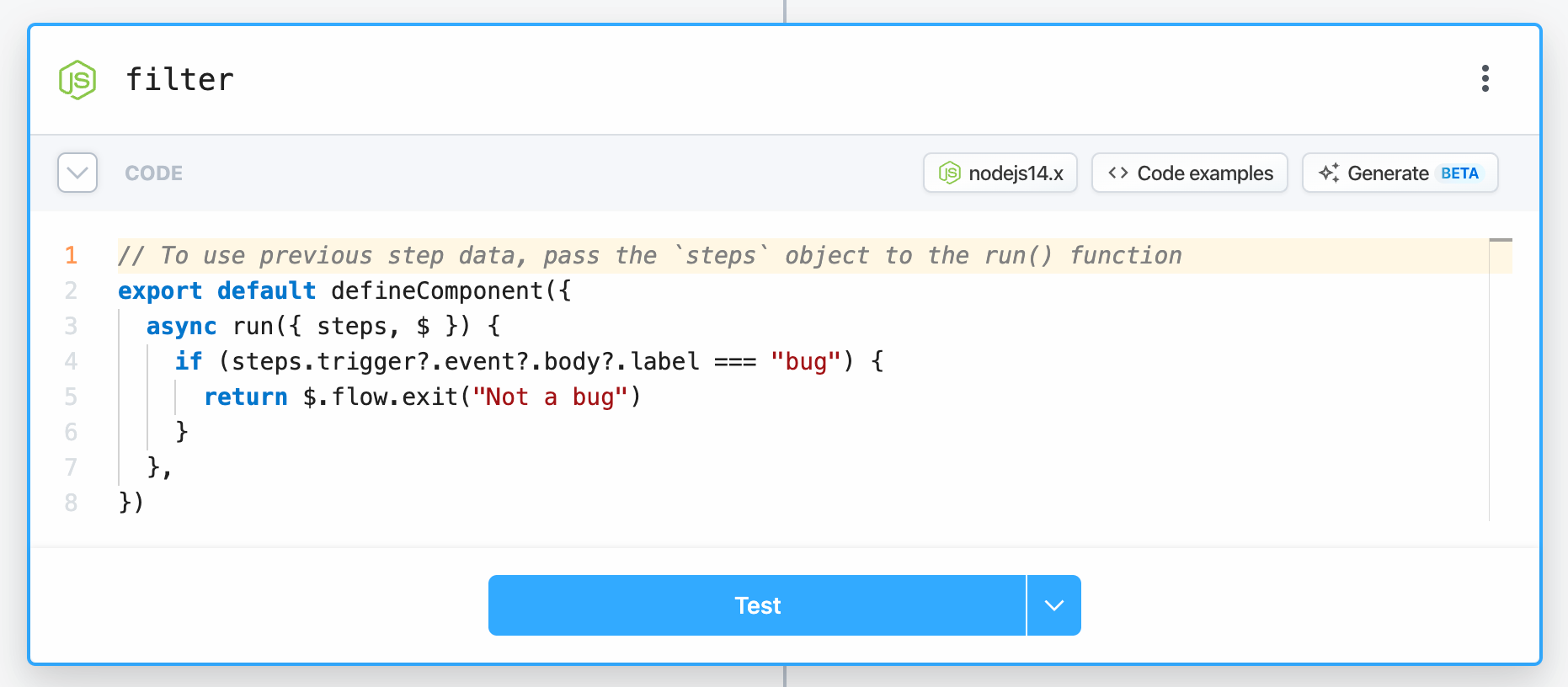
At Pipedream, we want to run workflows on bug, app, triaged labels, and more. Since workflows are a sequence of linear steps, we can end the workflow early if we get an event for another label we don't care about:
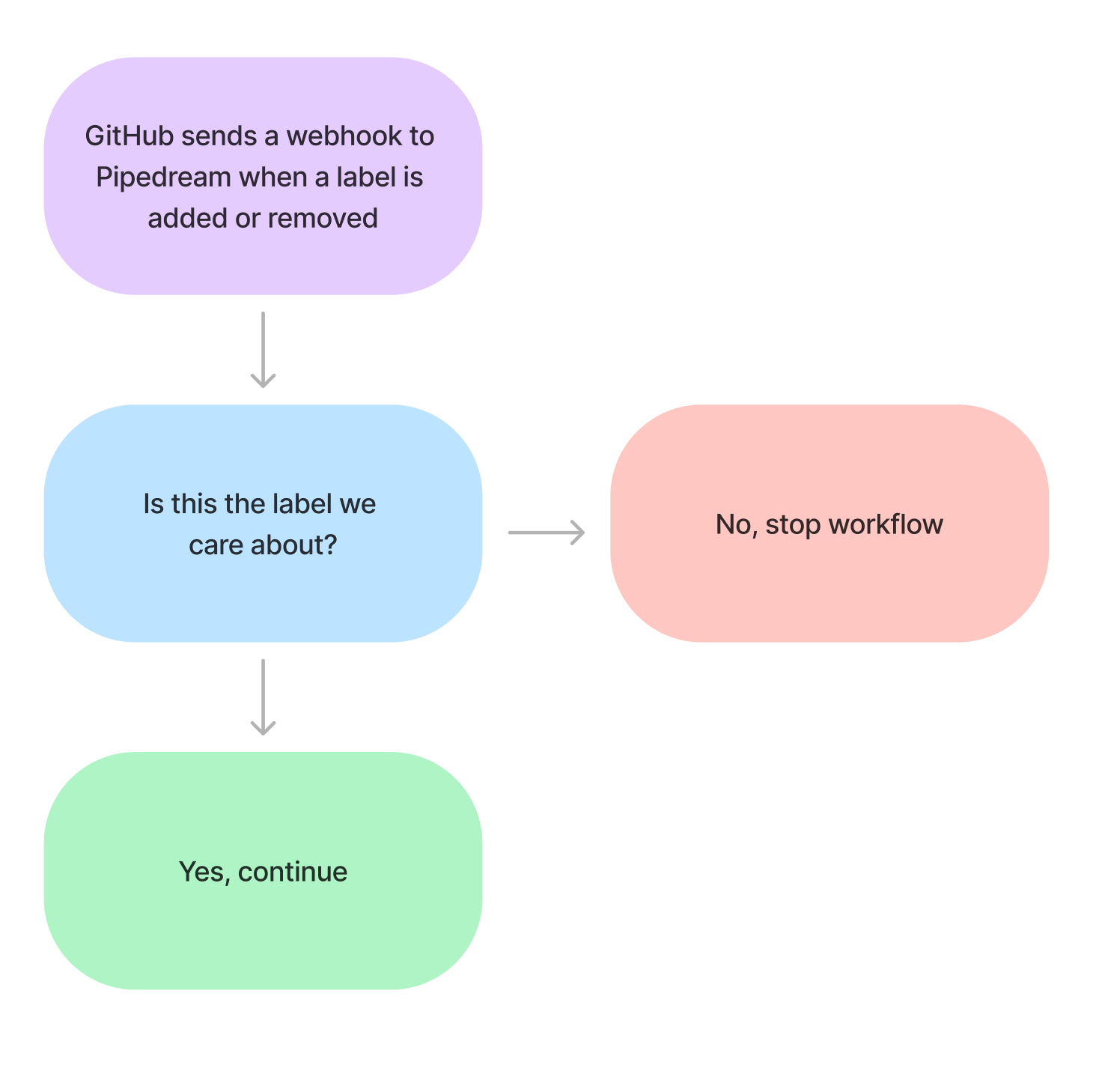
Use the Filter actions or end a workflow early in code to control when your workflow runs:
Add authentication and authorization
When you use an app-based trigger, Pipedream tries to validate the event using the guidance from the app provider. For example, many apps will pass a "signature" that encodes the data sent in the request along with a secret that you (or Pipedream) configures for the webhook. If you know the secret, you can decode the data and validate the signature, which helps confirm the event was sent from the app you expect and not some random server on the web. See the Stripe docs for an example.
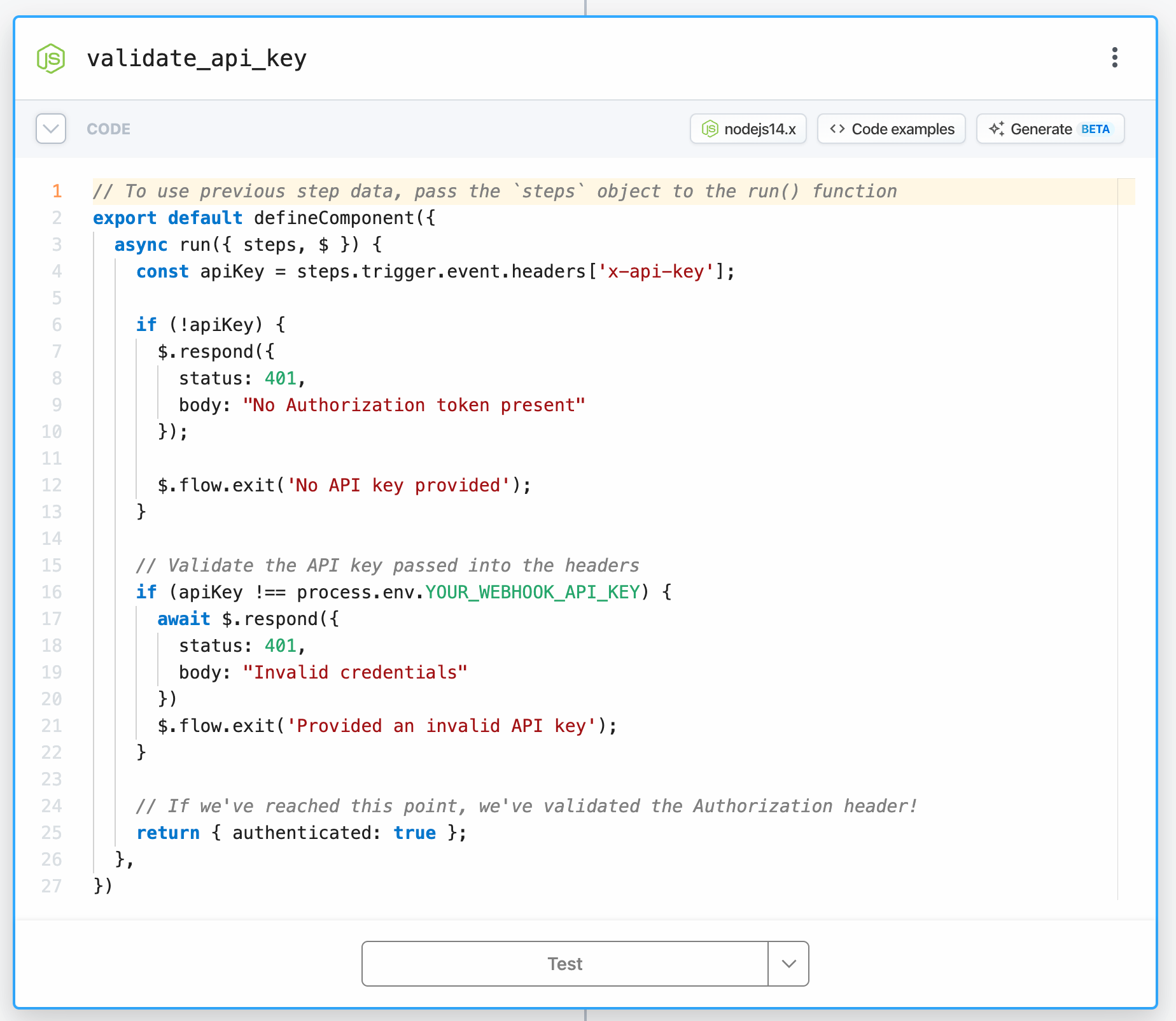
When you run your own HTTP endpoint, you should implement similar validation. Check out our Validate Webhook Auth action for common auth options.
If you want to add custom auth logic, you can do it in code. You can validate requests with HTTP Basic Auth (see example workflow), check JWT tokens to authorize requests from your app's users, or implement any kind of auth logic you want. In general, validate requests as strictly as possible.
Set the right workflow settings
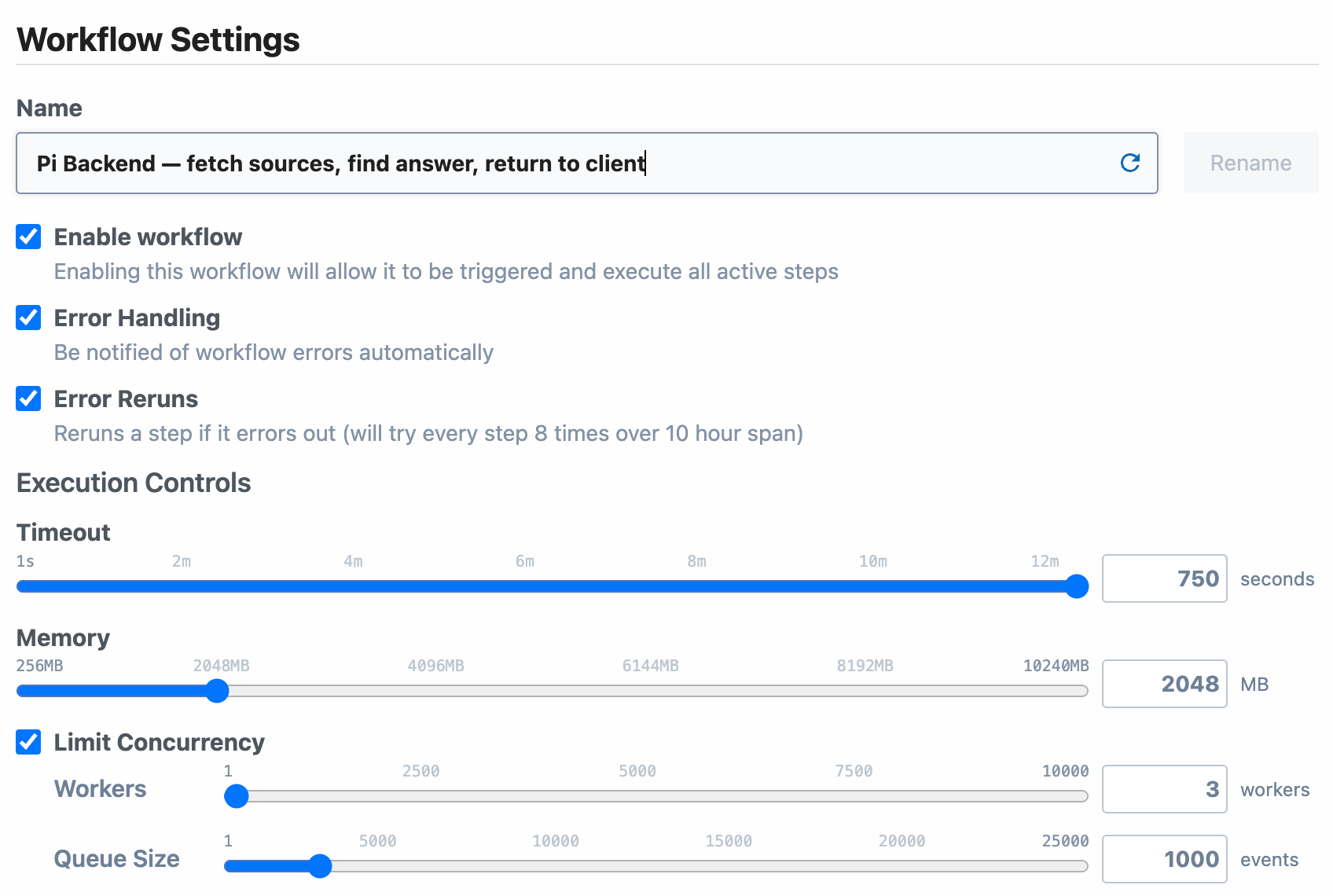
Pipedream provides a few workflow settings that can make your apps resilient to failure.
- Auto-retry failed executions — We configure auto-retry on almost every workflow we run. Workflows can fail for many reasons, and we generally want to retry the executions if they do. By default, executions will end as soon as they error. When you set auto-retry, you can run a workflow execution up to eight times automatically over ten hours.
- Choose the right timeout — By default, executions will time out at 30 seconds, ensuring you don't run more than one credit when you don't expect it. But complex workflows take a while to run. Test the average runtime of your workflow on real data. If it typically takes longer than 30 seconds, increase the timeout accordingly.
- Set the right memory — Like any app, some workflows are memory-intensive. If you see Out of Memory errors or know the memory constraints of your workflow, increase the memory.
- Configure concurrency and throttling controls — Many apps can run concurrently, without considering rate limits of third-party APIs. But you may need to configure these settings for real-world workflows. For example, if you're updating data in a data store or database, and need to guarantee consistency, you may want to set the concurrency of the workflow to 1 to ensure you don't overwrite data. If an API has a rate limit of 10 requests a second, you can set the workflow to run no more than that rate.
Use built-in actions
Like the trigger step, you should use pre-built Pipedream actions if they exist. If they don't, reach out and we'll help you build them.
Actions abstract common API operations — e.g. sending messages to Slack, writing data to a database, etc. — so you don't have to write the code yourself. When we build actions, we implement detailed guidelines and QA these integrations rigorously, so you can expect them to work. If you find any bugs, you can always reach out to our team or submit a PR yourself to fix the issue.
If you have the API docs for the service you're trying to talk to, you can also use our HTTP actions to send requests:
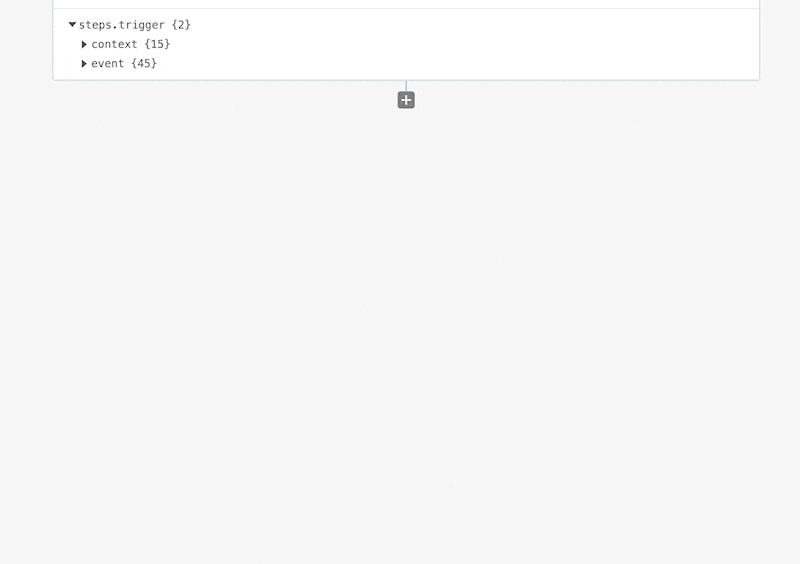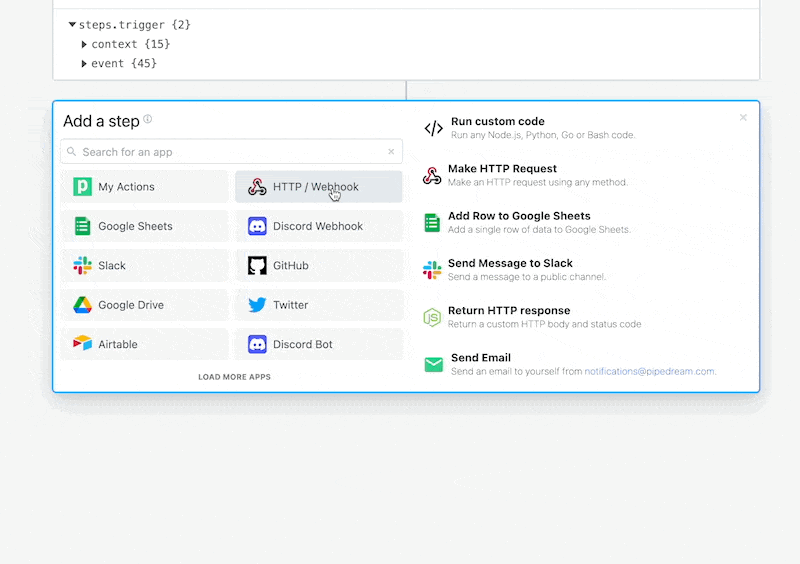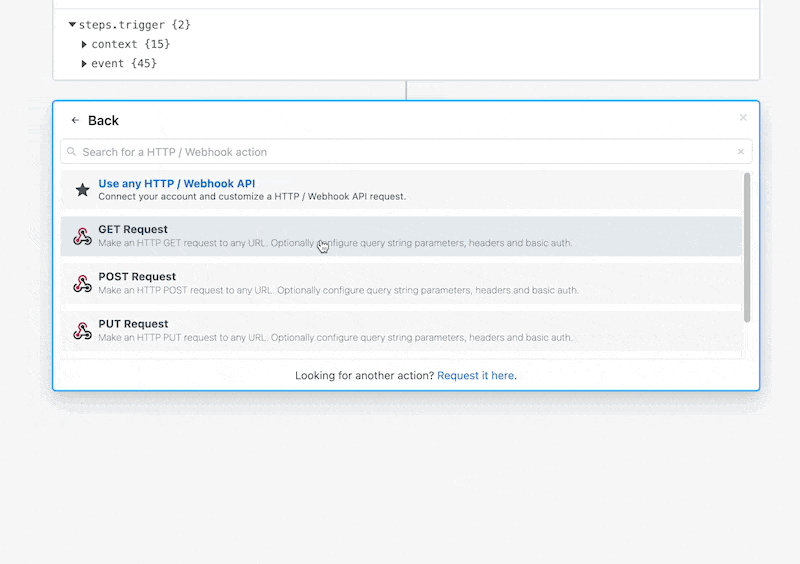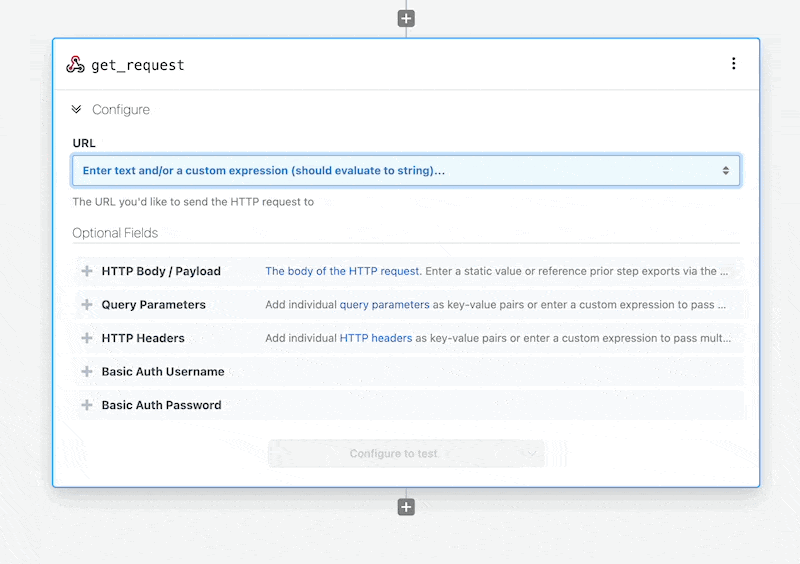
Handle known errors in code
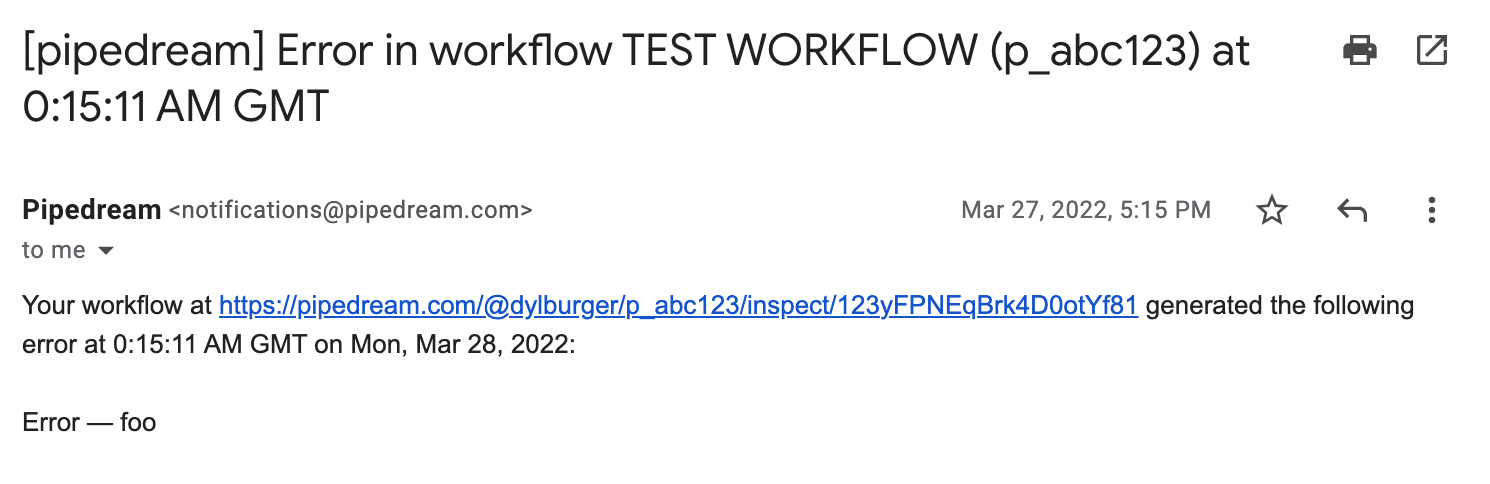
By default, workflows will send you emails or Slack notifications the first time a specific workflow raises an error in a 24-hour period. This means if the same workflow raises the same error 100 times, you'll only get a notification on the first error — you can look into it ASAP, but you won't be spammed. If it continues erroring after 24 hours, we'll send another email every 24 hours until you fix it.
When you know what kind of errors your code might raise, you can also write your own code to handle errors:
try {
await callSomeAPI()
} catch (err) {
throw new Error("This API threw an error I want to handle with custom logic: ", err)
}Any unhandled errors will send error notifications like the email above. So this custom try / catch logic can help when you want to send specific error messages or data to your error notification channel.
Consider a custom error workflow
Sometimes you need a detailed view into errors, and custom error handling for specific workflows. Consider a custom error workflow in these cases.
Pipedream exposes a $errors stream on every workflow. Each time an unhandled error is raised, we emit an event to this stream. You can subscribe another workflow to these events. That workflow will run on any errors from the original workflow. Pipedream also exposes a global $errors stream: you can run a custom workflow on unhandled errors in all workflows.
You can use this pattern in a few useful ways:
- You can send errors to Datadog, Sentry, or another centralized monitoring service.
- Many systems have the concept of a dead letter queue — a place where events that fail all retries are stored for later inspection. You can store failed events in a queue like SQS or Redis. Since workflows support multiple triggers, you can connect that queue to your workflow, in addition to the primary trigger. Then you can manually replay events from the queue, and that'll trigger the workflow like any standard event.
- Since you can run any code in a workflow, you can do anything you want to handle errors in custom ways.
Watch the video above to learn more.
Configure your own retry logic
Pipedream exposes functions in both Node.js and Python that lets you implement your own custom retry logic:
This behavior is very useful for handling errors and other unexpected issues. You can use it to retry failed API requests on a custom schedule, poll for the status of an external job, and more.
Use dead man's switches
The classic example of a dead man's switch is Google's Inactive Account Manager. If Google detects that your account is inactive after a few months, they'll follow up to ask if you're still active, then transfer ownership to someone else, or delete your account entirely.

But dead man's switches are so much more powerful than that. In general, you can use them anytime you want to be notified when something you expect to happen fails to happen in a certain amount of time.
You need to figure out two things to set up a dead man's switch:
- What event do you want to monitor? At Pipedream, we monitor sign ups, daily reports, and anything else we expect to happen regularly.
- When should you alert after inactivity? We generally get sign ups on https://pipedream.com every minute. If we've gone an hour without a single new user, there's probably an issue in our sign up flow.
We use AWS CloudWatch to configure these alerts.
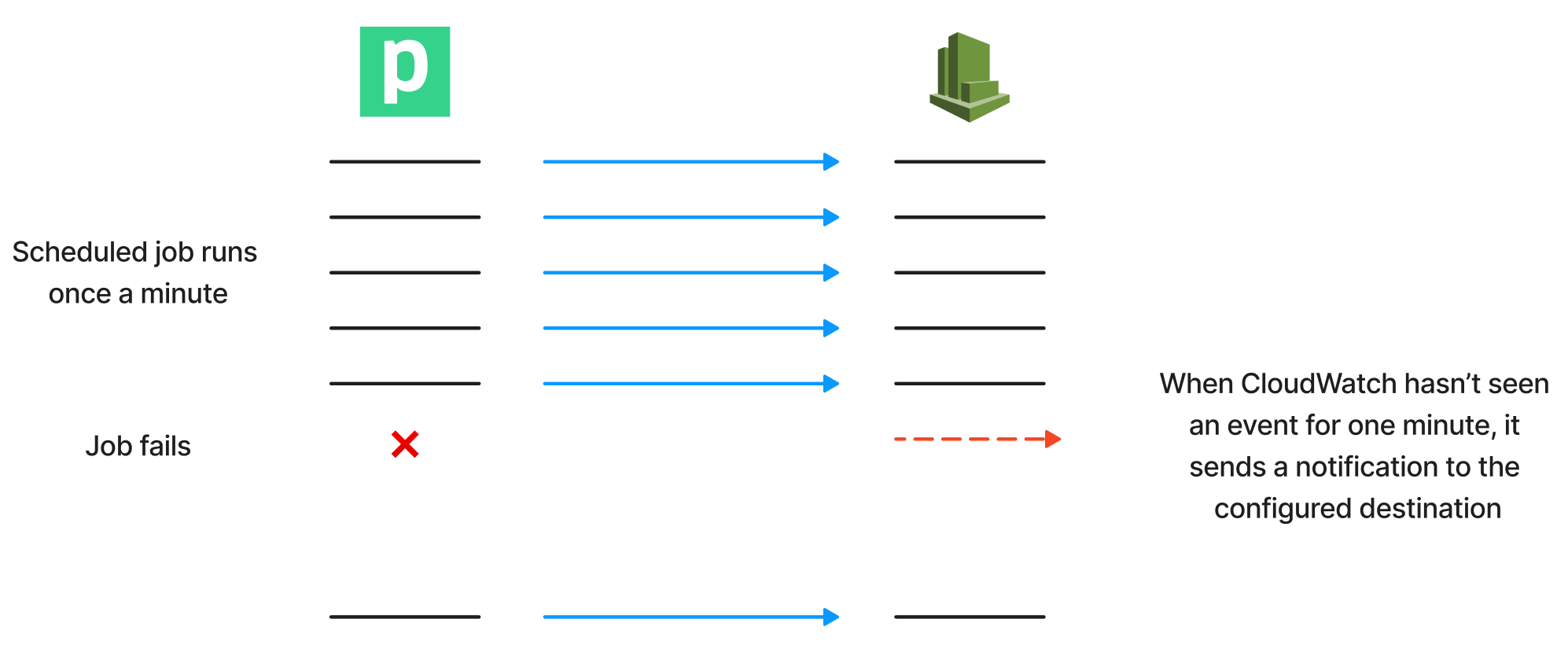
When the event we care about succeeds, we ping CloudWatch:
import AWS from "aws-sdk"
// Generates a single-element array of metric (count) data used for PutMetricData calls
function generateMetricCount(MetricName, Value) {
return {
MetricData: [
{
MetricName,
Unit: 'Count',
Value,
},
],
Namespace,
};
}
export default defineComponent({
props: {
aws: {
type: "app",
app: "aws",
}
},
async run({ steps, $ }) {
const { accessKeyId, secretAccessKey } = this.aws.$auth
const cloudwatch = new AWS.CloudWatch({
accessKeyId,
secretAccessKey,
region: 'us-east-1',
})
const Namespace = 'Pipedream/CoreMetrics';
$.export("metricResponse", await cloudwatch
.putMetricData(
generateMetricCount('Signups', 1),
).promise()
);
},
})Then we configure a CloudWatch alarm to notify us when we don't receive data. When we haven't seen a sign up in an hour, CloudWatch raises an alarm, which sends us a Slack message.
Monitor Pipedream
Like all cloud providers, Pipedream can suffer incidents. We recommend you subscribe to incident alerts from our status page. Monitor workflows using your own monitoring service. In addition to Pipedream, we use Checkly, CloudWatch, and Datadog to monitor our production services.
Questions? Talk to our team
Business and Enterprise customers get dedicated Pipedream engineers for support, along with an SLA. We offer Support contracts for all customers, and you can hire a Pipedream expert to build and maintain workflows for you. Reach out to support@pipedream.com if you'd like to learn more.