Build your own chat bot with OpenAI and Pipedream


Meet Pi, Pipedream's little AI helper. Pi is a support bot, trained on our docs, code, and integrated APIs. It answers questions in our Slack and Discourse communities. Like ChatGPT, it provides (mostly) human-level answers to challenging problems.

It's fun to talk to, it's saving us hours a day, and it's providing support to our community that we never could without an artificial assistant.
This week, we also updated Pi to use OpenAI's new Vision API, which lets us process screenshots and other media that Pi couldn't parse before.
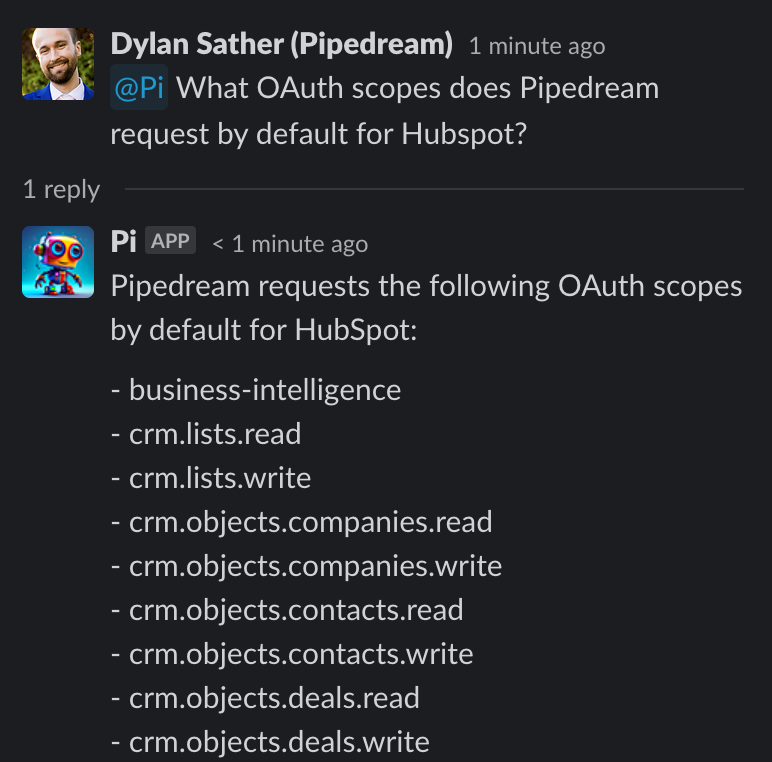
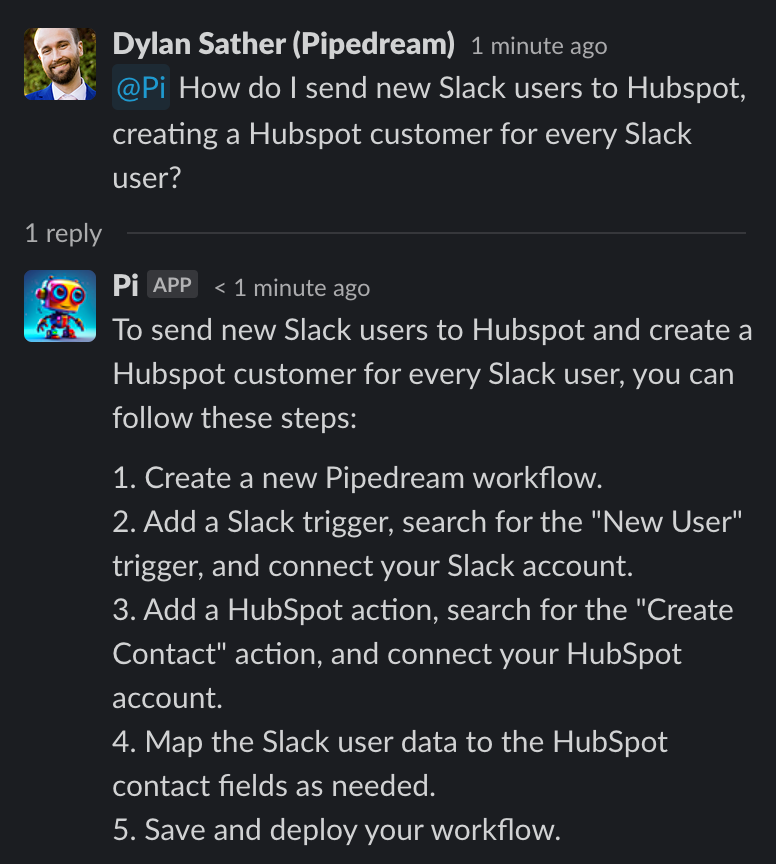
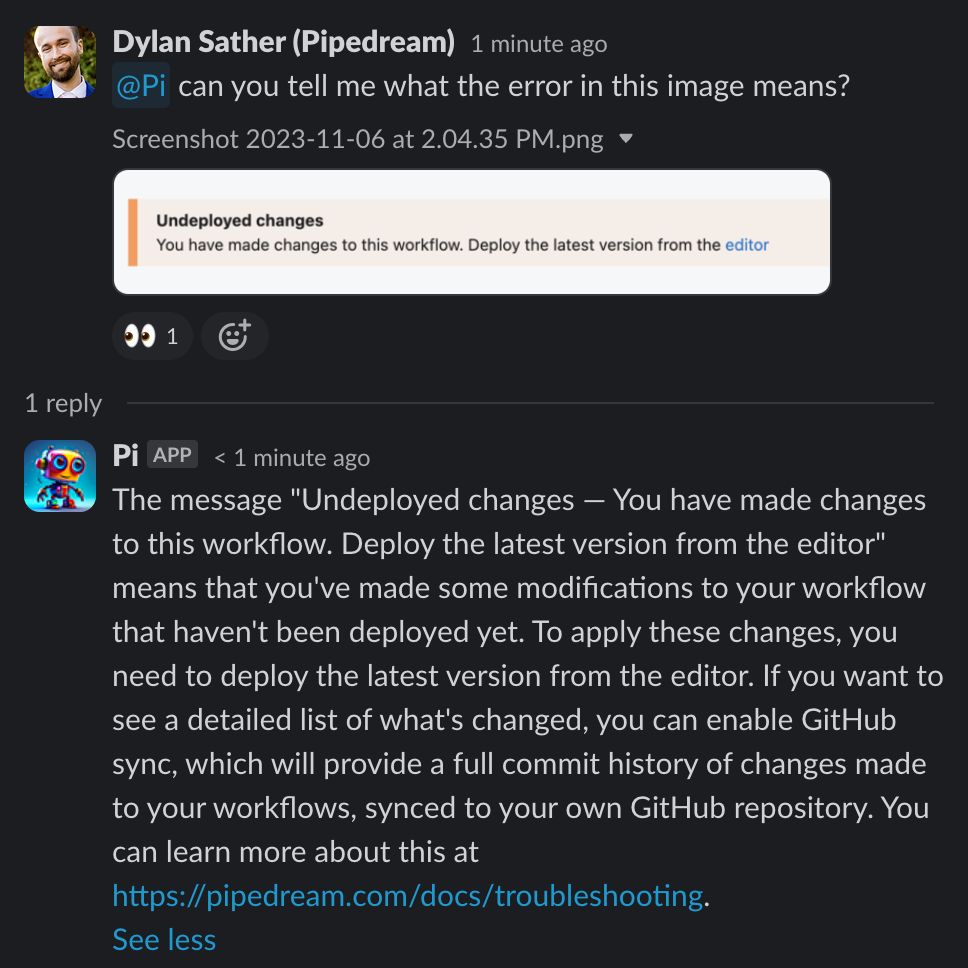
Collectively, we've spent hundreds of hours researching, refining, and deploying Pi. We've made amazing progress, but since this tech is so new and moving fast, we still find issues and improve it incrementally every day.
We're sharing everything we've learned so you can build your own.
Terms
This article assumes you know how to code — or want to learn — and are curious about building AI bots. But we don't assume knowledge of language models like GPT-4. Here's a few terms you'll see used in this post and more generally:
- LLM: Large language model. GPT-4 is an LLM, as is Meta's LLaMA. LLMs are trained on websites, papers, and other vast amounts of text, often from the Internet. They learn how to predict the next most-likely token to appear after the text the user provides. This is why you often hear token prediction referred to as "completion". We use OpenAI's GPT-4 model for Pi. As of 2023, GPT-4 performs better than other models on most problems.
- Token: A piece of a word, a unit of text that models like GPT-4 deal with.
- Prompt: The text you provide to the LLM. It can be a question, a set of instructions — any text.
- Completion: Since LLMs are predicting the next most-likely token that appears after a user's prompt, it "completes" that text. This is why you'll see this verb used when describing LLMs. See e.g. OpenAI's chat completion API docs.
- Embeddings: Embeddings are vectors that store the semantic meaning of a piece of text. (see OpenAI reference). If you want to compare the semantic meaning of two strings, compare their embeddings using a measure like cosine distance. Embeddings that are "close" in distance are more related. We'll discuss this all in more detail below.
Designing your bot
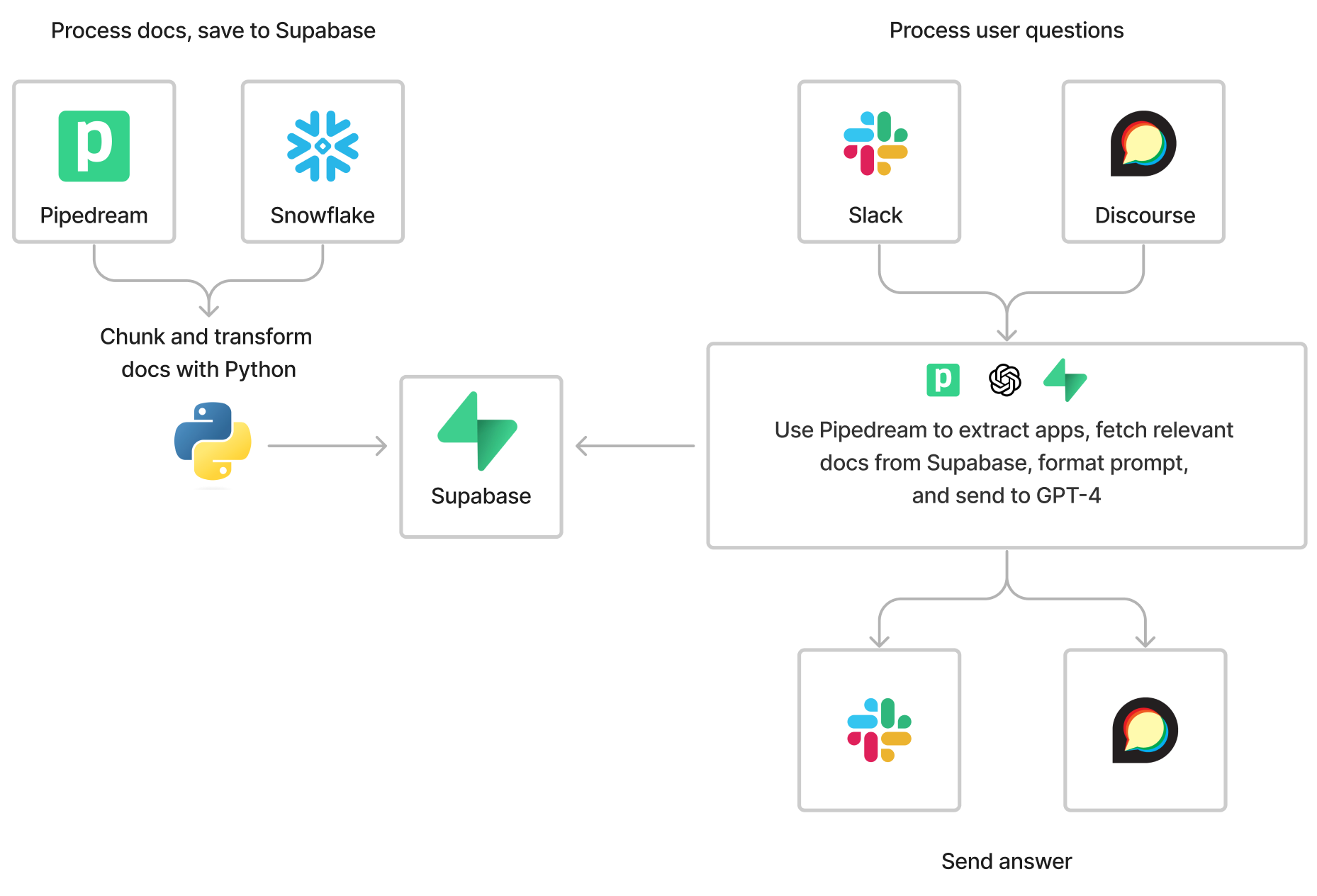
You should think through five key things when designing your bot:
- What docs / content does it need to answer questions?
- How are users going to interact with it? On Slack, email, UI?
- Given a question, how do you process it and retrieve the most relevant docs? In our case, users are often asking about app integrations, so we try to identify those apps in the question and retrieve relevant app metadata.
- What rules should it follow when communicating with users? How should it return its answers and links to docs? How should it respond when it doesn't know an answer? How should you include the docs from step #3 in the prompt to give the LLM more knowledge? This is where you'll develop the core instructions the LLM will use to answer questions.
- How do you evaluate and improve the accuracy of answers? You'll constantly find issues with your docs and your prompt. You need a way to evaluate and improve your bot's performance for all of your key use cases. You don't want to ship a subtle change to your prompt and introduce a major regression in its behavior in another area, as we've done many times.
We'll detail how we approached each of these below.
1. Your bot needs docs and knowledge
If you're building a bot to answer questions about your business, it's likely GPT-4 doesn't know everything about you. That was the case with Pipedream. Since we launched in 2019, it knows we exist. But we add new features, docs, and integrations daily, we don't know all the public docs the model is trained on, and GPT-4 has a knowledge cutoff — a date where its knowledge ends. So today, it can't answer deep questions about the Pipedream product or API.
If ChatGPT returns reliable answers for your use case, and you don't care about events or updates after a certain date, you may be able to skip this part. Everyone else should read on.
Retrieval augmented generation
So how do we solve this problem? Enter Retrieval Augmented Generation ("RAG"):
- Retrieval: Given the user's question, retrieve relevant docs / content
- Generation: Pass the docs, along with the original question, to the LLM
A base model like GPT-4 is generally very good at summarizing text, classifying input, writing code and more. But it lacks the specific information it needs to answer your users' questions. When you provide that context with the question, the LLM provides better answers.
At this stage, you need to figure out what docs you need, how to process them, and where you're going to store them.
Choosing the right docs
Only use trusted docs. For example, your pricing page, terms of service, and your product's docs can be considered trusted sources. But your community Q&A, blog posts from external authors, and other user-generated content are not necessarily vetted.
We originally included community Q&A, but it reduced the accuracy of answers. Some posts matched the user's question, but were unanswered or had wrong answers. Others referred to years' old features that had since been improved or deprecated. After a few attempts to separate good posts from bad, we removed them entirely and saw our accuracy improve.
Today, we use our docs, pricing page, terms and privacy page, our blog, and our integrations data: information on the app, all of the sources and actions you can use on Pipedream, and the OpenAPI specs and docs of our partners.
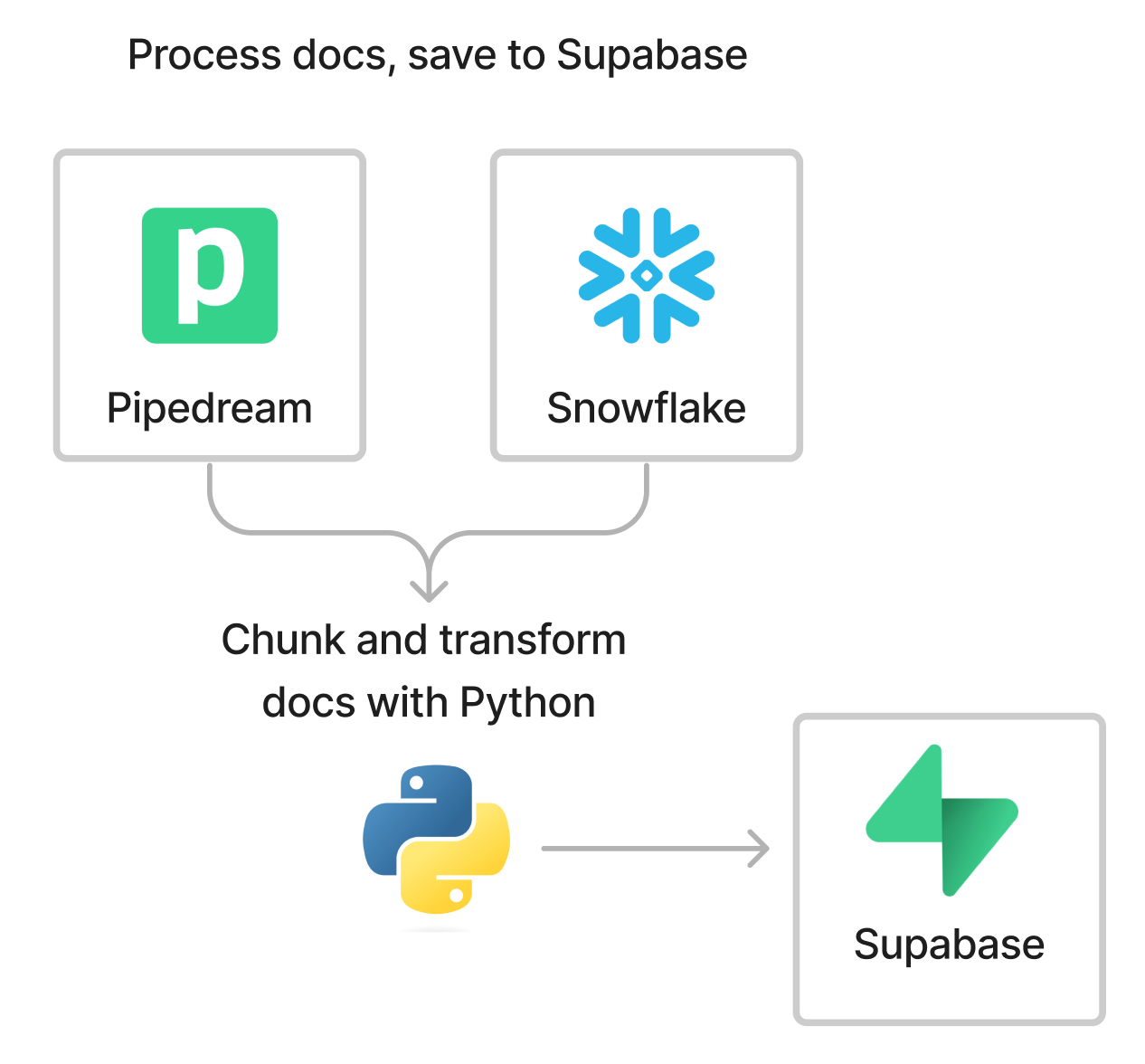
We run this Jupyter notebook to fetch, process, and save docs into Supabase. We use Python because of the availability of text processing and AI client libraries. For example, we use PyTorch and scikit-learn to customize our embeddings — Python is the de-facto language for this use case.
Since the notebook processes Pipedream docs and custom Snowflake tables, you'll need to modify it for your use case. We'll walk through the core parts below so you see how this works.
Chunking
Chunking refers to the process of dividing a large document of text into smaller pieces. Typically, we need to do this for two reasons:
- OpenAI and other LLM APIs have token limits, so to fit the user's question, docs, and answer, you can't pass every doc every time. These limits are rising — the newly-announced GPT 4 Turbo model supports
128Ktokens per request — but since commercial LLMs charge per token, you'll want to minimize tokens to only the required information. - You want your bot to retrieve docs similar to the user's question. If you store pages of docs with a range of different concepts in a single record, the embeddings created from that will encode meaning about the document as a whole, and not any individual sections. We like to think of chunks as a section of text that maps to a unique concept.
To separate our docs into chunks, we used two utilities from LangChain:
- For Markdown docs,
MarkdownHeaderTextSplitter - For HTML docs,
HTMLHeaderTextSplitter
When saving chunks, there should be some overlap between sections. For example, chunk 2 should contain the end of the text from chunk 1 and the start of the text from chunk 3. Since adjacent sections of docs are likely related, this keeps semantic context between these related chunks when they're saved as independent sections.
I haven't seen a one-size-fits-all answer for how large your chunk size or chunk overlap should be. According to Pinecone, embeddings with the latest OpenAI models work best when chunks are multiples of 256 tokens. But these should be tested and optimized for your use case.
## TEXT SPLITTERS ##
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
]
text_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
## h2 and h3 sections of our Markdown docs separate logical sections
markdown_headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=markdown_headers_to_split_on)Docs and data should be structured
You should convert your docs to Markdown or another structured format as a part of the processing — if they are not already — with separate content in separate sections, delimited by headers like # and ##. In practice, we've found that the inherent structure of headings, text, and other formatting communicates structure and meaning better than the same HTML. OpenAI also uses Markdown for their own prompts, so we think it's a safe bet.
Take note, OpenAI constructs prompts using markdown. I believe this is reflective of their instruction tuning datasets.
— Mike Conover (@vagabondjack) October 15, 2023
In our own work we’ve seen markdown increase model compliance far more than is otherwise reasonable. https://t.co/VniaLFbO2B
You'll see in our notebook how we retrieve data from Snowflake and convert that to Markdown text, which details how users can use our integrations in the Pipedream UI. Specifically, we convert data about our integrations to numbered instructions that tell users how to configure our triggers and actions, which Pi can use directly when talking to users.

Brex's prompt engineering guide and Anyscale's RAG guide highlight other techniques for passing structured data to the LLM. Experiment with your own data and keep iterating.
Convert the docs to embeddings
Once you have chunks of docs, you can convert them into embeddings.
Embeddings are vectors that store the semantic meaning of a piece of text. Embedding models accept text like "What's the temperature outside?" as input and converts it to a vector of numbers.
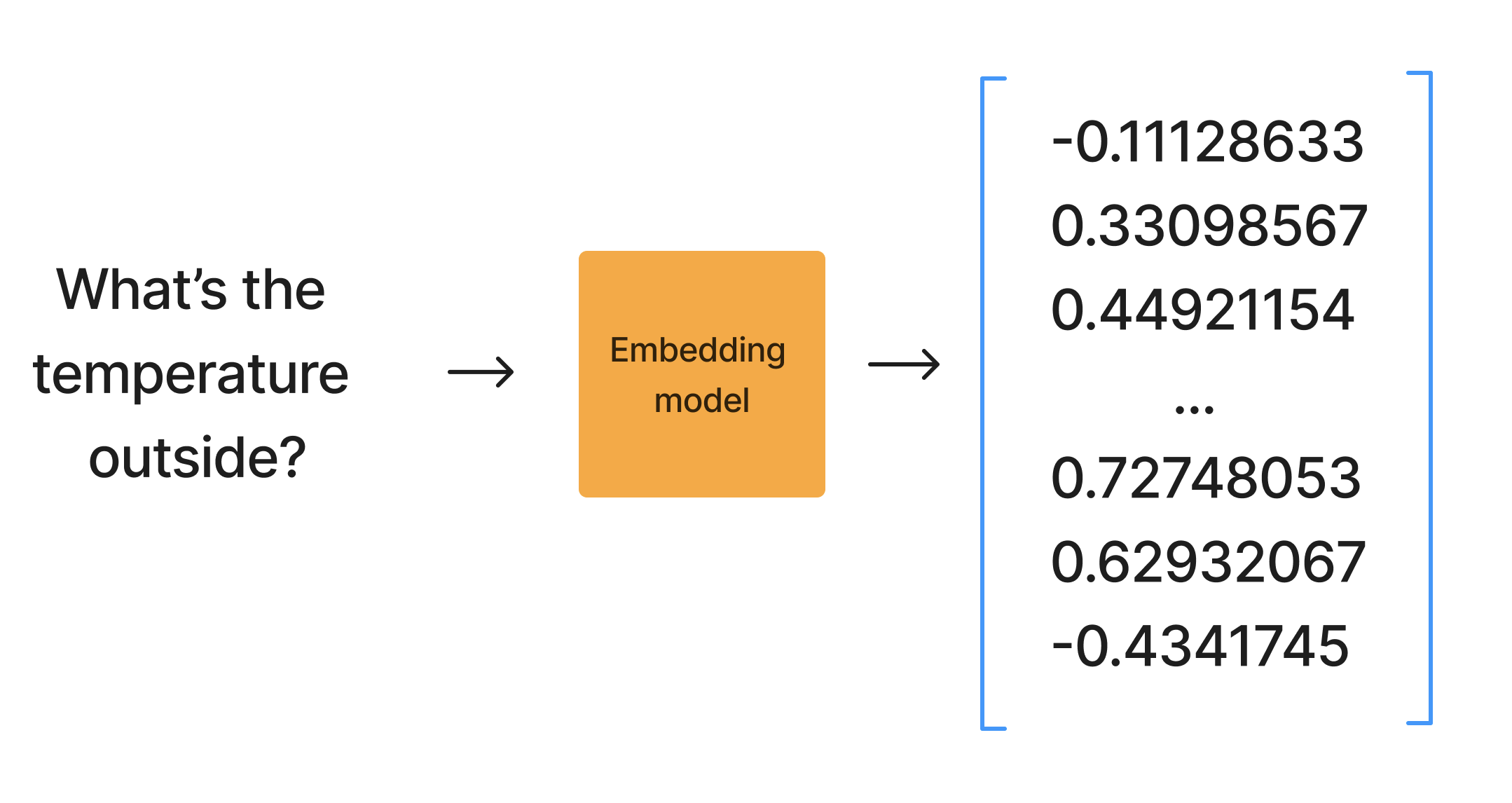
Since these numbers represent semantic meaning, if you want to compare the meaning of two strings, compare their embeddings using a measure like cosine distance. Embeddings that are "close" in distance are more related. You don't have to understand the math behind this — cosine distance is implemented in many libraries.

We use LangChain's OpenAIEmbeddings class to generate embeddings with OpenAI. You can use the OpenAI Embeddings API directly, or use an entirely different service like Cohere or your own embeddings model to generate embeddings.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
embedded_docs = embeddings.embed_documents(docs)OpenAI embeddings that use the latest text-embedding-ada-002 model are vectors of 1536 numbers. embedded_docs is a Python list of lists of embeddings. We'll store this alongside the docs content below.
Store your docs and embeddings
Now you need to save your sources and embeddings in a data store. We evaluated many different options — primarily Pinecone and PostgreSQL — and landed on Postgres for reasons I'll describe below.
We quickly realized that we'd want to return a complex set of docs based on the user's query:
- Fetch all docs that matched the embeddings (via vector similarity)
- Do a standard full-text search (people call #1 + #2 "hybrid search")
- If we can identify apps in the user's question (e.g. "Slack", "Discord"), retrieve all integration docs tied to the app. This includes everything on https://pipedream.com/apps — the OAuth configuration for apps, test code, and information on all triggers and actions.
Docs are returned in order of descending similarity, so if we have to truncate content to fit into the 8K GPT-4 token limit, we'll (theoretically) get the best content at the top.
Postgres is mature and the pgvector extension provides the vector operations we need to compare embeddings. It was also easy extend our Postgres queries to do the full-text search and integration docs retrieval:
SELECT content
FROM docs
WHERE app = 'slack'WHERE clause, which is part of the reason we chose PostgresLike with chunking, consider your data and retrieval model, and test different providers. A different embedding model may work better for your use case, and Postgres may not be the optimal place to store your content. This is an important step to get right. Your bot will provide poor answers if it's given bad docs, so it's worth the time.
2. Interface with users
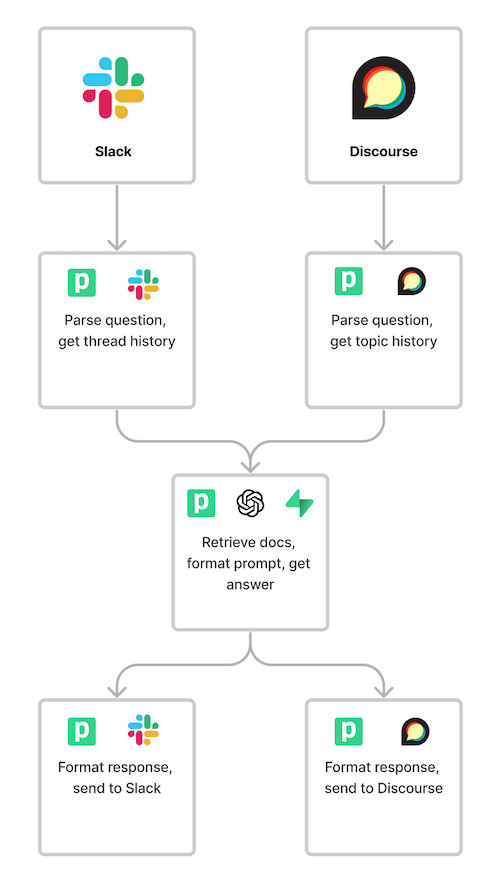
We use Slack and Discourse for community support. Pipedream supports triggers and actions for these apps and hundreds more. So we've built Pipedream workflows to handle incoming questions and pass them to Pi to answer.
With Slack, Discourse, and other messaging apps, you don't need to manage your own UI. Even Midjourney — with millions of users — still uses Discord for their core app.
OpenAI's Chat Completion API also accepts chat history. These platforms store chat history for you, so you don't need to maintain that state yourself. The app-specific workflows just retrieve chat history directly from Slack or Discourse when a new question arrives.
For example, we've configured the Pi Slack app to send app_mention events to this workflow. The workflow fetches thread history, processes attachments, and sends this payload:
{
"question": "test",
"chat_history": [],
"channel": "public_slack",
"meta": {
"channel": "C046G5HMU75",
"thread_ts":"1699465441.545199",
"files":[]
}
}meta contains channel-specific information, which is passed to the workflows that send Pi's answer back to the user.to the core workflow that fetches docs, constructs the prompt, and sends it to GPT-4 to answer the question.

This workflow runs asynchronously, pulling user questions from a queue, keeping the concurrency of our workflow to 5 running workers at a time to avoid hitting OpenAI rate limits. This introduces latency during peak periods, but late answers are better than no answers at all, and users don't expect immediate responses via these channels. We also enable auto-retry in case of error, and run a dedicated worker to process questions as quickly as possible.
The next two sections cover how this workflow works and some of the lessons we've learned about docs retrieval and prompt engineering — two key parts of building a good chat bot.
3. Fetch the right docs
In section 1, we stored all the docs and knowledge our bot needs to answer questions. But we can't pass all of these docs to GPT-4: we're limited to 8K tokens per request and we want to minimize cost. So we need to identify the docs that best match the user's question.
We also want to identify all possible data that'll be useful to Pi. The more accurate data, the higher the accuracy of our answers. For us, this data includes text from screenshots and app integrations tied to the user's question, and we talk about those steps below. You probably have very different data that's important to your bot, but we hope the examples get you brainstorming.
Extracting text from images
With OpenAI's new Vision API — aka GPT-4V — we can process images. This is huge. Our users frequently attach screenshots of errors, API docs, and code, so we can process them and pass that context to Pi.
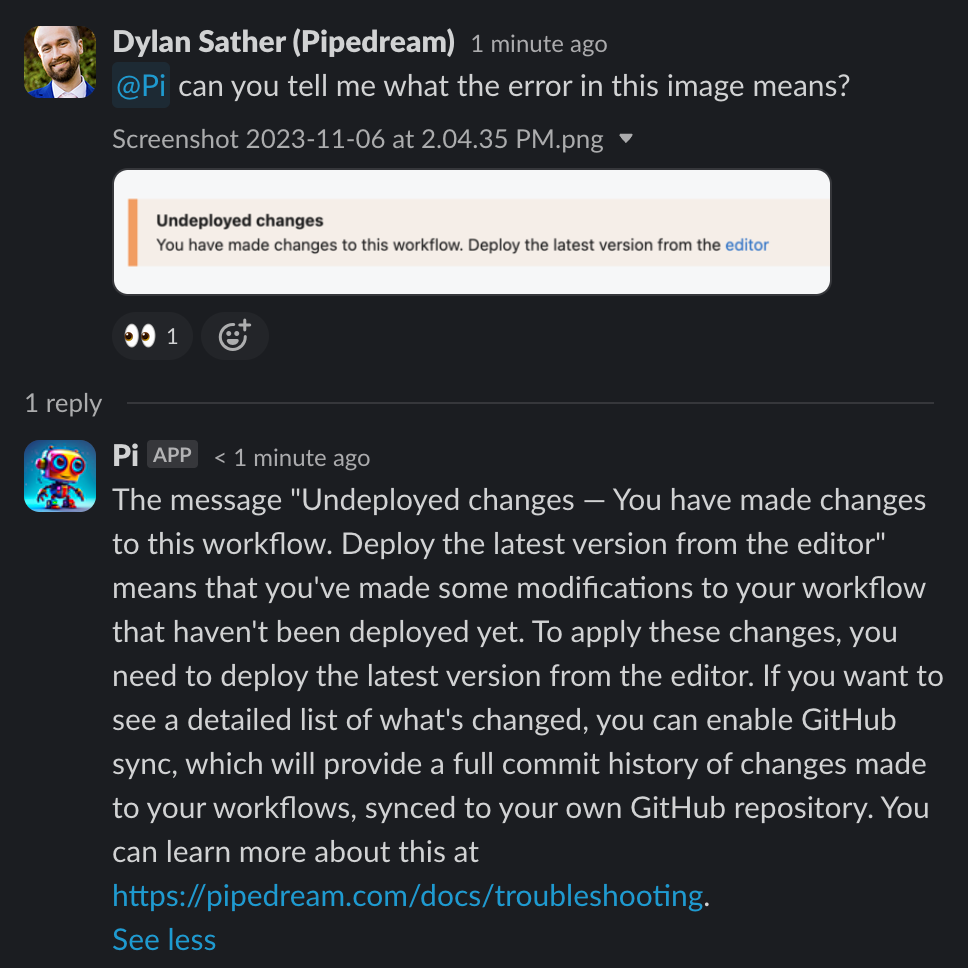
The get_files_and_get_content_with_openai step of the workflow downloads any files attached to the user's Slack message and asks GPT-4V to return the text, which we can include in the prompt we send to GPT-4.
const content = await axios($, {
url,
headers: {
Authorization: `Bearer ${this.slack.$auth.oauth_access_token}`,
},
responseType: 'arraybuffer',
});
// Format the image for OpenAI
// See https://platform.openai.com/docs/guides/vision
const image_url = `data:image/jpeg;base64,${Buffer.from(content, 'binary').toString('base64')}`
const resp = await openai.chat.completions.create({
model: "gpt-4-vision-preview",
messages: [
{
role: "user",
content: [
{ type: "text", text: "Can you return all of the text present in these images? Please put each section of text on its own line." },
{ type: "image_url", image_url },
],
},
],
});Extracting apps
API integrations are fundamental to our business — it is what we do. Over half of all questions ask about one or more apps, e.g.
- How do I connect Google Sheets and Trello?
- How do I send an email with AWS?
The extract_apps step of the workflow does a fuzzy match between the text in the question and the list of apps we support, retrieved from a Pipedream data store in the list_records step above. If we can identify apps in the question, we can retrieve useful metadata about the app — its configuration, OAuth scopes, etc. — that a keyword or embeddings search may not directly yield in its top results.
One cool thing to note: the vision API step used Node.js and this step uses Python, all in the same workflow — just use the library or language that works best to solve each problem.
Create embeddings from question, retrieve docs, hit GPT-4
We saved embeddings for all of our docs in Supabase. So when we search for docs that match the user's question, we also have to generate the embeddings for the question using the same text-embedding-ada-002 model as before. The create_embeddings step does that.
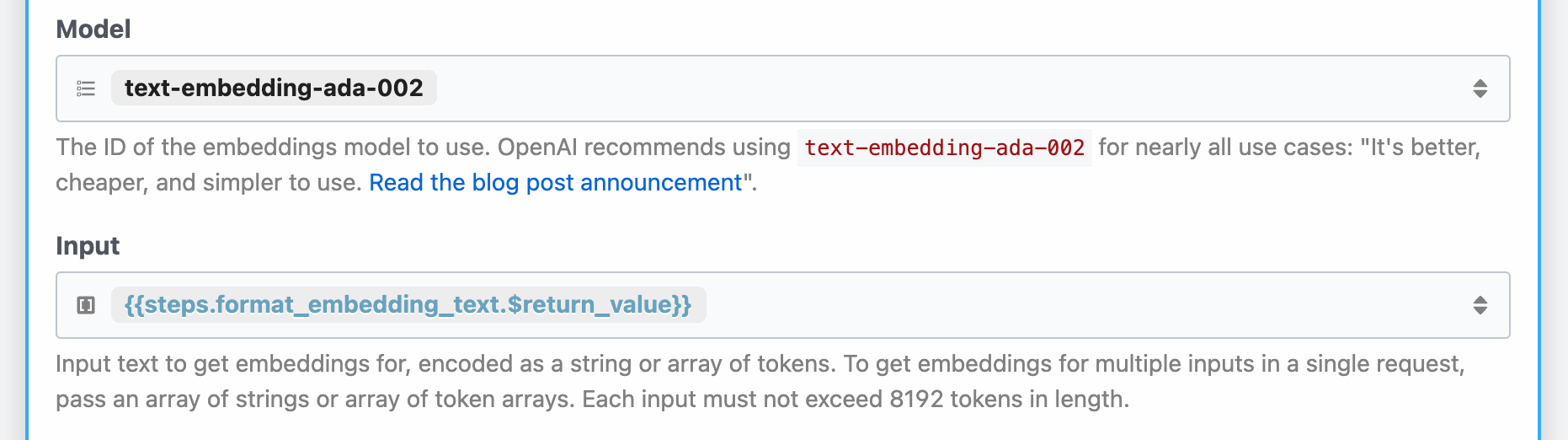
Now we can retrieve the docs that best match the original question. Recall that when we chose Postgres, we wanted to run a search that combined the best results of three queries:
- Docs matching the embeddings (via vector similarity)
- Docs matching a standard full-text search
- If we identified any apps, the data on those app integrations.
The fetch_vectors step handles that hybrid search. We implemented a match_documents function from this Supabase post on pgvector, and the kw_match_documents function from this LangChain doc on hybrid search.
4. Write your prompt
In 2022, everyone said, "learn to code". Now we're telling people, "learn to write".
The hottest new programming language is English
— Andrej Karpathy (@karpathy) January 24, 2023
Your #1 goal when developing your prompt is to map everything you want your bot to know to structured English (Markdown). We'll pass in a clear set of rules for how the bot should answer specific questions, information retrieved from our docs, a strict output format for our answers, and more. Our final prompt looks something like this:
## System instructions
...
## General rules
...
## Rules for writing Node.js code
...
## How you should answer questions
Given the rules above, and the docs below, answer the user's question.
## Docs
...
### App metadata / API docs
...
## User question
Question: ${userMessage}
## Attachments
The user attached images in the message, which had the following text: ${steps.get_files_and_get_content_with_openai.$return_value.join('\n\n')}
---
Answer: "Prompt engineering" has reached its hype stage, but it's core to building a good bot. I'd recommend trying any prompting tips you find when you're learning. I've picked up random hacks or links to research papers that have proved useful for our domain, like Chain of Thought or the Reason and Act (ReAct) model.
But most prompt engineering just involves writing clear, structured English. You'll see how we prompt Pi in the call_gpt step of the workflow.
System Instructions
You're a helpful Pipedream support bot and autoregressive language model that has been fine-tuned with instruction-tuning and RLHF. You carefully provide accurate, factual, thoughtful, nuanced answers and code, and are brilliant at reasoning.
You help users answer question about Pipedream. You're an expert at writing Pipedream component code.
Try to use the information in the sources in user messages to answer the question, if possible. If you don't know the answer, you MUST follow up with questions to try to solicit more information from the user to arrive at an answer. You should be very, very skeptical you know an answer if you don't see it in your sources or the information you've been trained on. You also must not keep responding with the same answer over and over again — try to vary your responses and keep them short if the user is asking the same question.
This is important for my career. You better be sure of your answers.We pass these system instructions on every request, and have modified it heavily over time. It's a been formed from a combination of observations, results of research papers, and our own, Pipedream-specific instructions. For example, we added the section on skepticism because we've noticed Pi was overconfident with answers, even when it wasn't passed any sources. Afterwards, it was more cautious.

General rules
Then we define other, basic rules for how Pi should operate.
# Rules
Below you'll find a list of rules for how you should answer questions and produce output. Please read them carefully. They are all critical. Consider them your constitution — any output that violates them is against the law.
## Rules for how you should answer questions
These rules are listed in no particular order.
1. DO NOT attempt to answer greeting with with "Hello, world!" examples. Greetings like "Hello" or "Hi" are not requests for Hello, World examples.
2. If you sense frustration or negative sentiment from the user, you should respond apologetically. Direct them to visit https://pipedream.com/support for more support options.
2b. If the user asks to talk to a human / person / someone on Support, direct them to visit https://pipedream.com/support for more support options.
...Pricing questions
Math is notoriously difficult for LLMs, since they have not been trained for that purpose. But we try to get Pi to answer questions as best it can, directing users to our pricing page if it can't.
a. Any pricing questions will probably yield HTML documents that define pricing plans, FAQs, and other information on pricing. Parse the structure / content of these files as data and use it to answer pricing questions.
5b. If the user asks a question about pricing, plans (Free, Basic, Advanced, Business, Enterprise), costs, credits, or other pricing-related questions, think step-by-step. For example,
Question: How many credits are on the Business plan?
Thought: This requires using my sources at https://pipedream.com/pricing
Action: Lookup information in the https://pipedream.com/pricing SOURCE_URL below
Action Input: "How many credits are on the Business plan?"
Observation: I see a Business plan that includes 5,000 credits a month to start, and a cost per credit after.
Final Answer: The Business plan includes 5,000 credits a month to start, and charges a cost for additional credits after the 5,000 base. Please see https://pipedream.com/pricing for more details.This prompt uses a technique from the Reason and Act (ReAct) paper, which shows performance improvements on reasoning tasks when you instruct the machine to observe, reason, and answer step-by-step.
Rules for writing code
We provide a large list of instructions to help Pi write code on Pipedream. The Pipedream runtime exposes a special API not available in Node.js or Python, and GPT-4 can't write perfect Pipedream code, so we provide that knowledge directly in the prompt.
You can read the code for the full prompt, but you'll see we clearly define the API, the output format, instructions on how to use our axios client, and more.
The first and foremost rule: when you're asked to write code, you MUST return Pipedream component code.
I need to teach you what a Pipedream component is. All Pipedream components are Node.js modules that have a default export: \`defineComponent\`. \`defineComponent\` is provided to the environment as a global — you do not need to import \`defineComponent\`. \`defineComponent\` is a function that takes an object — a Pipedream component — as its single argument.
// many rules follow...The key takeaway for you: identify what the LLM doesn't know about your use case and teach it explicitly in the prompt, with plenty of examples.
Managing token budgets
Recall that we're limited to 8K tokens in the GPT-4 model, across the question and answer. We've implemented some code to manage this budget. When we have long chat history or a lot of docs content, we truncate it to make sure we fit within the limit.
// There is no magic in these numbers. Just best-guesses at the proportion of context each section should provide.
const OPEN_AI_TOKEN_LIMIT = 8192 - systemInstructionsTokens.length;
// Allocate 20% of budget to docs, or lower if the docs are shorter
let DOCS_SOURCES_TOKEN_LIMIT = Math.min(Math.round(.20 * OPEN_AI_TOKEN_LIMIT), docsTokens.length);
// Allocate 10% of budget to chat history
const CHAT_HISTORY_LIMIT = 1000
const chatHistoryTokens = encode(JSON.stringify(chatHistory))
const CHAT_HISTORY_TOKEN_BUDGET = Math.min(chatHistoryTokens.length, CHAT_HISTORY_LIMIT)
// etc.Weighting our sources
Our queries against Supabase returned the full URL to the doc and a similarity score between the doc and the user's question, ordered by that score.
const sources = steps.fetch_vectors.$return_value
// Sort sources by similarity in case we have to truncate
const sortedSources = sources.sort((a, b) => b.similarity - a.similarity)
const docs = sortedSources.map(s => `SOURCE URL: ${s.url}\n\CONTENT: ${s.body}\n\nSIMILARITY: ${s.similarity}`).join('\n\n---------------------\n\n')We tell GPT-4 to weight the knowledge in these sources in its answers:
10. A source's SIMILARITY defines its cosine distance to the provided question and answer. Higher similarity scores are better — use that weighting to guide your answer.Processing input, returning output
Remember that these are "completion" models. They're designed to predict the next-most-likely token to appear given the text in the original message. This is why we end the prompt with:
Question: ${User question}
---
Answer: Send the answer
After it receives a response from GPT-4, the workflow sends the final answer and sources to to the intended destination. For example, the core workflow triggers this notification workflow for Slack, which creates a formatted message and sends it as a reply on the original thread. The same happens for Discourse.
5. Evaluate and improve accuracy
Your bot is likely to perform well on common questions where you have clear docs. In other cases, it'll provide incorrect but confident answers that will waste your users' time. Be skeptical of your bot's performance and carefully interrogate its answers for flaws.
Getting your bot to answer 100% of questions accurately is the hardest part of this process. As your product evolves, you'll constantly find new issues that need to be addressed with better docs or better prompts. You need to monitor its accuracy and develop a system to identify and fix bugs. Here's a few things we do.
Have a test suite
When we ship a new change, we use this workflow to send a flurry of test messages to Slack.
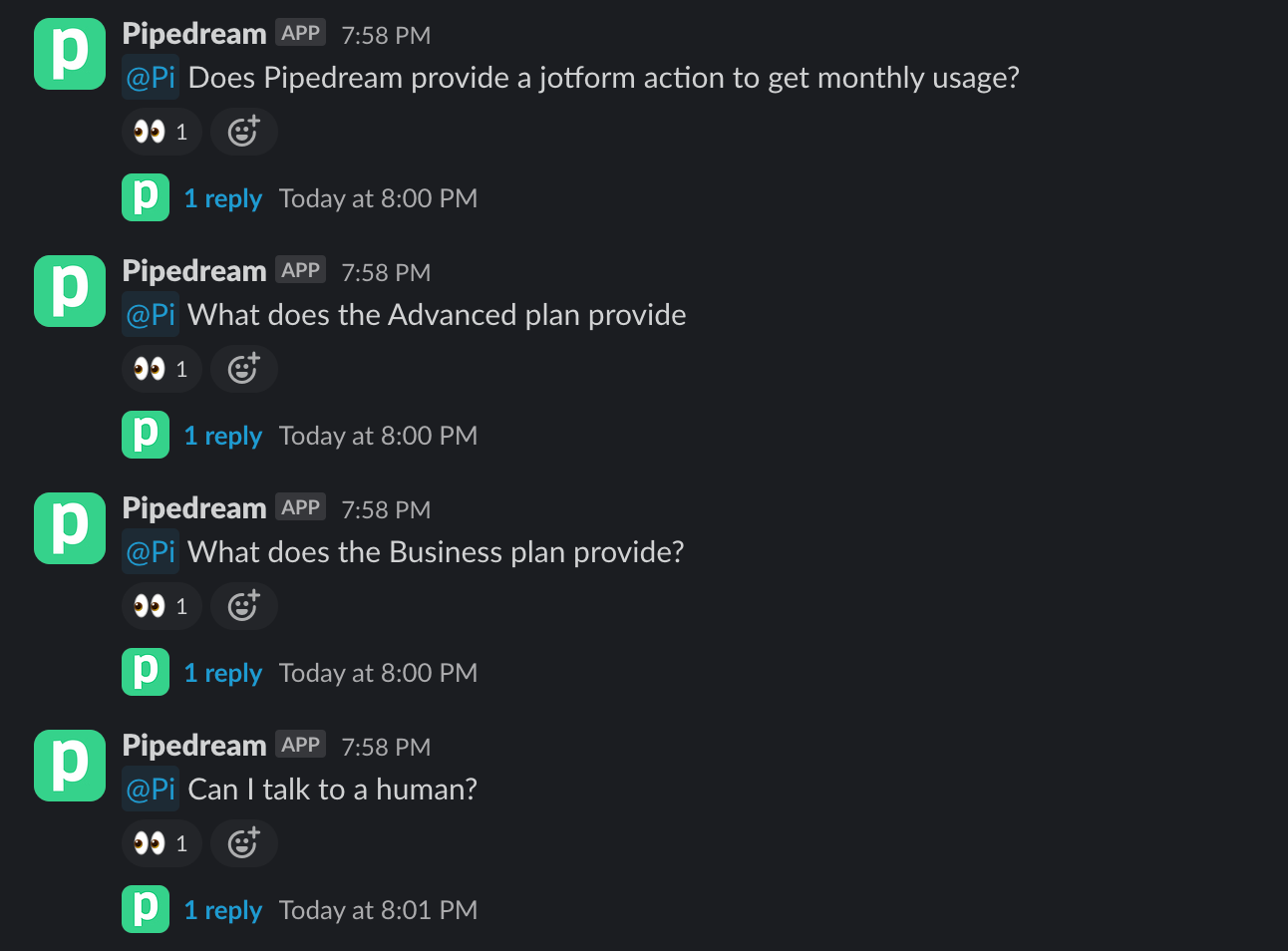
Each message is a test case: we're asking pricing, integrations, billing, and other random questions that have previously elicited poor responses. Like any test suite, we need to make sure Pi doesn't regress on core questions.
Whatever test suite you develop, use real questions from your users. Add short prompts with limited information to simulate users who will ask things like "help" or "pricing".
Many better tools exist for LLM unit testing and we're excited to test them as we improve Pi.
Review bad answers and iterate
Develop a system to log and review bad answers. We log every question, answer, and sources to a Google Sheet for later evaluation. At this stage, we're still constantly monitoring Pi's ability to answer real questions. And we can generally classify bad answers into two categories:
- We passed bad docs to Pi, e.g. they were out-of-date or had a bug in the code.
- Pi's response was poor given good information. In this case, we're providing good docs, but Pi didn't interpret them correctly.
We try to monitor every interaction with Pi. If it returns a bad answer because of bad (or no) docs, we add the 📚 emoji, which triggers this workflow. It pulls the thread history from Slack, summarizes it with OpenAI, and creates a new GitHub issue asking us to add better docs:
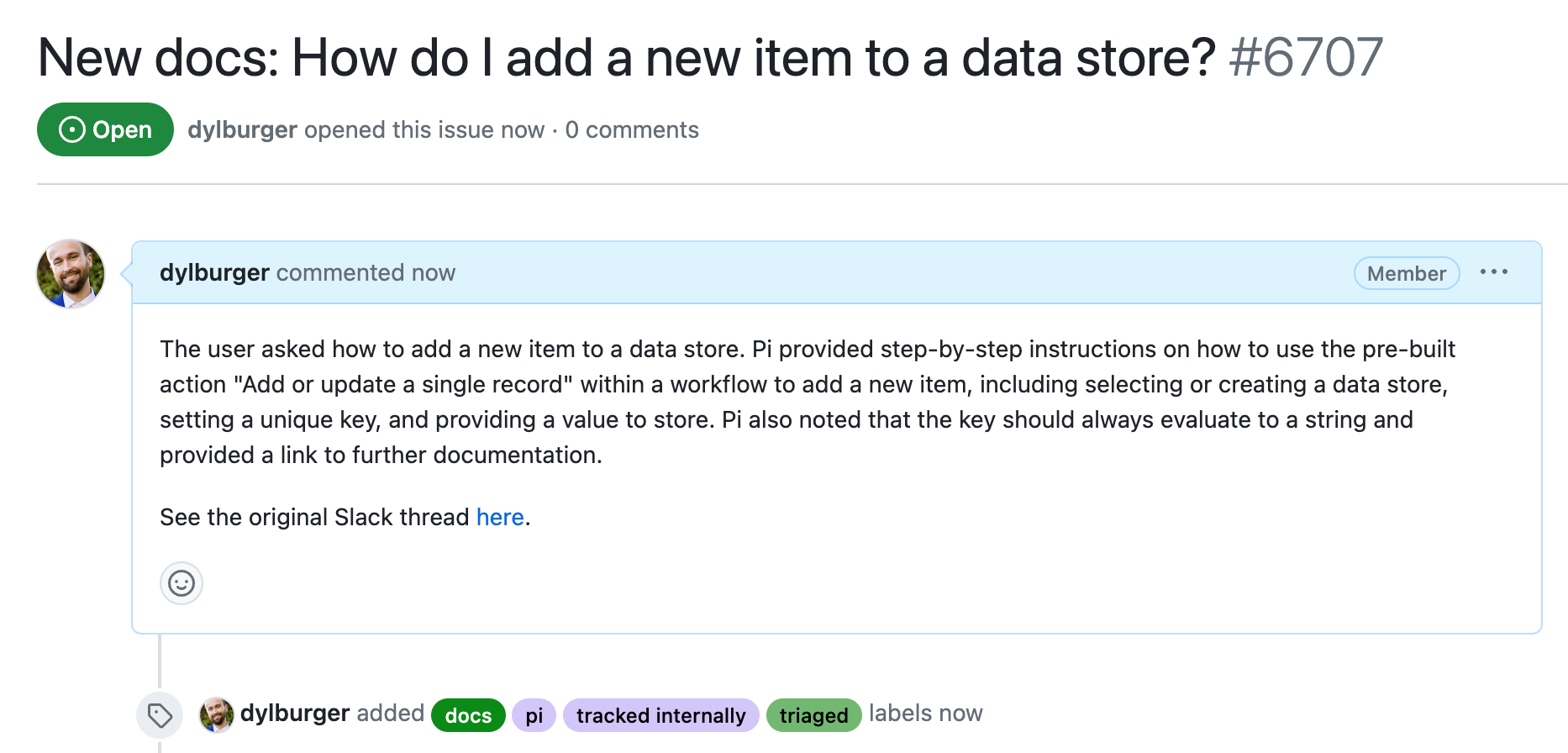
Adding the ⚙️ emoji triggers the same workflow, but adds a different title and labels:
const { reaction } = steps.trigger.event
const titlePrefix = reaction === "books" ? "New docs" : "Pi improvement"
const labels = reaction === "books" ? ['docs', 'pi', 'tracked internally'] : ['pi', 'tracked internally']
return await octokit.rest.issues.create({
owner: "PipedreamHQ",
repo: "pipedream",
title: `${titlePrefix}: ${title_summary}`,
body: `${longer_summary}\n\nSee the original Slack thread [here](${permalink}).`,
labels,
});Advanced: Rate your sources, use that to fine-tune your embeddings
If you're building a bot to answer questions on well-researched concepts like history and politics, you may not need this step. If you're building a bot for a product like Pipedream, you might want to fine-tune your embeddings.
Read through this amazing Twitter thread, which references this Jupyter notebook from OpenAI.
Boost your Semantic Search with Customized Embeddings 📈
— Glavin Wiechert👨💻 (@GlavinW) February 20, 2023
1️⃣ Gather similar/dissimilar pairs
2️⃣ Train a matrix to highlight relevant aspects of your embedding
3️⃣ (Original Embedding)×(Custom Matrix)=(Custom Embedding) pic.twitter.com/1HT0XmfPAO
Here's the core idea:
- Run your embeddings similarity search against common questions (e.g. if you're using Supabase, run the
match_documentsfunction from this blog post). Return the top 5 sources. - For each source, record a
1if it's relevant to the user's question and a-1if it's not. We wrote a Pipedream workflow let us ask questions and retrieve docs directly in Slack. We rated each source with a 👍 or 👎 and saved the question, doc, and rating in a Google sheet. - Create a CSV of records with with the fields
text_1,text_2, andlabel. Put the question intext_1, the content of the docs intext_2, and the1/-1inlabel. - Load the data into this Jupyter notebook and run through the code, adjusting it as necessary for your embedding model and your data. It uses PyTorch to train a model that learns from in the feedback you provided.
This produces a numpy array that you can save locally and upload as a workflow attachment. The main workflow loads this array and takes the dot product of the array and the original embeddings from the user's question:
import numpy as np
def handler(pd: "pipedream"):
custom_embeddings_matrix = np.load(pd.steps["trigger"]["context"]["attachments"]["custom_embeddings_matrix.npy"])
modified_embeddings = np.dot(pd.steps["create_embeddings"]["$return_value"]["data"][0]["embedding"], custom_embeddings_matrix)
return modified_embeddings.tolist()This took us a long time to fully understand, but once we worked through the notebook and applied it to our embeddings, we started returning better docs and getting better answers from GPT.
Tend the garden, keep iterating, and ask questions
These are not set-it-and-forget-it projects. They require maintenance and tuning. The tech and APIs are new. We're still writing new docs, editing the prompt, and testing new techniques. But what we've shipped is working well, and it's providing a needed technical support function for our community that we couldn't provide otherwise.
Please join us the Pipedream Slack and Discourse communities if you have any questions about Pi, want to chat with it yourself, or just want to talk about AI and automation.