Get the latest count of confirmed cases, recoveries and deaths from the Wuhan Coronavirus via an HTTP API

A few days ago I started searching for an API to programmatically get the latest data about the global coronavirus outbreak. I came across several visualization and scraping projects, but I couldn't find a simple way to query the latest data programmatically — so I created an HTTP API that returns the latest data in JSON format using a Pipedream workflow.
The API fetches the latest number of confirmed cases, recoveries and deaths from a public Google Sheet published by the team at the Center for Systems Science and Engineering (CSSE) at John Hopkins University, and returns both the raw regional breakouts as well as summary stats in JSON format. It also caches the data for up to 5 minutes to improve performance. The raw data is aggregated by the team at the CSSE from multiple sources including the WHO, CDC, ECDC, NHC and DXY, and updates are published to Google Sheets multiple times per day.
Using the API
To use the API, just make an HTTP request to the following endpoint URL:
https://coronavirus.m.pipedream.net/You can test it in your browser or app, by running curl https://coronavirus.m.pipedream.net/ in a terminal, or copy and run this workflow.
The API returns:
- Summary stats (count of cases, recoveries and deaths)
- Global
- Mainland China
- Non-Mainland China - Raw data (counts by region as published in the Google Sheet)
- Metadata (including when data was last published and the cache status)
Note: Data is cached using $checkpoint to improve performance. The cache is updated if it's more than 5 minutes old (view the workflow code or read more below).
Sample API Response
Following is a sample of the data returned by the API. Note: the rawData array is truncated in this example to only show a single result — query the endpoint URL to retrieve the full response.
{
"apiSourceCode": "https://pipedream.com/@/p_G6CLVM",
"cache": {
"lastUpdated": "2 minutes ago",
"expires": "in 3 minutes",
"lastUpdatedTimestamp": 1580925783250,
"expiresTimestamp": 1580926083250
},
"summaryStats": {
"global": {
"confirmed": 24630,
"recovered": 1029,
"deaths": 494
},
"mainlandChina": {
"confirmed": 24405,
"recovered": 1020,
"deaths": 492
},
"nonMainlandChina": {
"confirmed": 225,
"recovered": 9,
"deaths": 2
}
},
"rawData": [
{
"Province/State": "Hubei",
"Country/Region": "Mainland China",
"Last Update": "2/5/20 16:43",
"Confirmed": "16678",
"Deaths": "479",
"Recovered": "538"
},
],
"dataSource": {
"googleSpreadsheetId": "1wQVypefm946ch4XDp37uZ-wartW4V7ILdg-qYiDXUHM",
"range": "Feb05_1220PM!A1:F1000",
"dataLastPublished": "44 minutes ago",
"googleSheetLastModified": "2020-02-05T17:27:39.593Z",
"publishedBy": "John Hopkins University Center for Systems Science and Engineering",
"ref": "https://gisanddata.maps.arcgis.com/apps/opsdashboard/index.html#/bda7594740fd40299423467b48e9ecf6"
}
}eCapabilities
The workflow behind this API uses the following capabilities and it runs on Pipedream for free (view, copy, modify and run the workflow code):
- HTTP trigger
- Node.js code steps
- Google and Moment.js npm pacakges (to use any npm package, just
requireit — nopackage.jsonornpm installrequired) - Auth managed by Pipedream (for Google Sheets and Drive)
- $checkpoint (maintains state across workflow executions)
- $respond() (returns an HTTP response to a client)
- Step exports (provides observability into data and enables workflows to pass data to later steps via the
stepsobject)
How It Works
The HTTP API works by triggering the Node.js code in this workflow on every request to https://coronavirus.m.pipedream.net/. The workflow consists of multiple steps to fetch and cache new data, transform and aggregate it, and finally respond to the client.

Next, I'll explain some of the key steps in the workflow.
steps.trigger
When you select an HTTP / Webhook trigger, Pipedream automatically generates a unique endpoint URL to trigger your workflow code. Since I'm sharing the endpoint URL publicly (https://coronavirus.m.pipedream.net/), anyone can make a request to execute the code and get the response.
steps.filter_favicon_requests
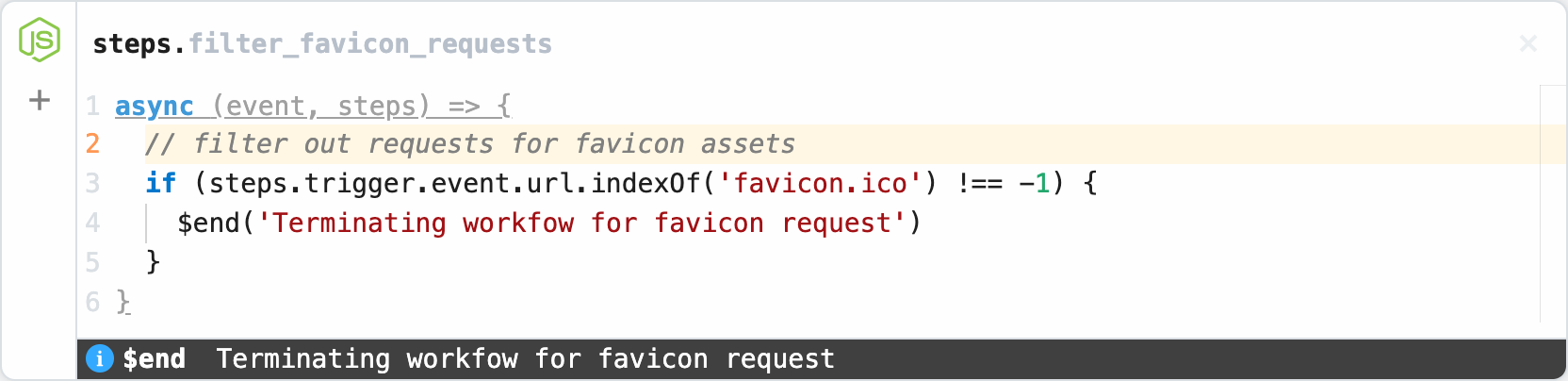
The first code step filters out duplicate requests caused by web browsers requesting a favicon.ico asset when loading the endpoint URL — if the the triggering URL contains favicon.ico, the workflow execution ends early and no additional steps or code are executed.
if (steps.trigger.event.url.indexOf('favicon.ico') !== -1) {
$end('Terminating workfow for favicon request')
}steps.get_data
Next, we either refresh the cache with the latest data from both Google Sheets and Google Drive (using the googleapis npm package with auth managed by Pipedream), or we return the data cached to this.$checkpoint.
First, we initialize this.checkpoint if it is undefined:
if (typeof this.$checkpoint === 'undefined') {
// initialize this.$checkpoint
this.$checkpoint = {}
this.$checkpoint.data = {}
this.$checkpoint.ts = 0
this.$checkpoint.lastModified = ''
this.$checkpoint.range = ''
this.$checkpoint.spreadsheetId = ''
this.$checkpoint.lastPublished = 0
}Then we determine whether the cache should be updated. There are two processes that will trigger a cache refresh:
- I'm running a separate workflow on a schedule to update the cache every 4 minutes. That workflow simply makes a request to the endpoint URL for this workflow and passes
refreshas the value of the query parameteraction, and the environment variableprocess.env.CSSE_NCOV_REFRESH_TOKENas the value for of the query parametertoken. The goal for this secondary process is to improve performance for end users, since it's slower to fetch and process live data from Google Sheets (ideally, the only time the cache is updated is via this out of band process). - However, if a user attempts to retrieve data by making a request to the API and the cache is older than 5 minutes, then that should also trigger a real-time lookup to Google Sheets will be triggered (this should only happen if #1 above fails)
this.dataExpiry = 5 * 60 * 1000
if (((new Date().getTime() - this.$checkpoint.ts) > (this.dataExpiry)) ||
(event.query.action === 'refresh' && event.query.token ===
process.env.CSSE_NCOV_REFRESH_TOKEN)) {
this.updateCache = true
} else {
this.updateCache = false
}
Note: I'm using the step export this.updateCache to determine whether to fetch new data because I'm going to reference this value in a later step (I'll be able to reference this value as steps.get_data.udpateCache). Using step exports also provides default observability into exported data, so I can easily see what condition was triggered for each event:

Finally, if this.updateCache is true, then we fetch the latest data using the googleapis npm package and save it to this.$checkpoint (which maintains state across workflow executions). Otherwise, we simply return the value of this.$checkpoint.
if (this.updateCache === true) {
// fetch the latest data from the Google Sheet
console.log('Fetching new data')
const {google} = require('googleapis')
const auth = new google.auth.OAuth2()
auth.setCredentials({
access_token: auths.google_sheets.oauth_access_token
})
const sheets = await google.sheets({
version: 'v4',
auth
});
this.$checkpoint.spreadsheetId = params.spreadsheetId
let response = await sheets.spreadsheets.values.get({
spreadsheetId: this.$checkpoint.spreadsheetId,
range: params.range
})
this.$checkpoint.data = response.data
this.$checkpoint.ts = new Date().getTime()
// get the date/time the file was last modified
auth.setCredentials({
access_token: auths.google_drive.oauth_access_token
})
const drive = await google.drive({version: 'v3', auth});
this.$checkpoint.lastModified = (await drive.files.get({
fileId: this.$checkpoint.spreadsheetId,
fields: params.fields
})).data.modifiedTime
// check if the tab name was updated
// which indicates new data was published
if (response.data.range !== this.$checkpoint.range) {
this.$checkpoint.range = response.data.range
this.$checkpoint.lastPublished = this.$checkpoint.lastModified
}
} else {
console.log('Return cached data')
}
return this.$checkpointNote: I connected my Google Sheets and Drive accounts to this step and used the auths object in code to securely pass the oauth access token to Google's API for authentication. E.g.,
const auth = new google.auth.OAuth2()
auth.setCredentials({
access_token: auths.google_sheets.oauth_access_token
})If you copy the workflow into your account to modify and run it yourself, then you'll need to connect your own accounts.

steps.transform_data
The data returned from Google Sheets in the previous step is an array of arrays representing the rows and columns of data in the sheet. This step makes the data more ergonomic by transforming the data into an array of JSON objects, with each value matched with its respective key (based on the value in the header).
const transformedData = [], originalData = steps.get_data.$return_value.data.values
let rowCount = 0
originalData.forEach(function(row){
if (rowCount > 0) {
let obj = {}
for (let i=0; i<row.length; i++) {
obj[originalData[0][i]] = row[i]
}
transformedData.push(obj)
}
rowCount++
})
return transformedDatasteps.summarize_data
This step returns a JSON object with the total count of confirmed cases, recoveries and deaths, as well as subtotals for Mainland China and non-Mainland China. The data is cached to this.$checkpoint and it uses the updateCache export from steps.get_data to determine whether to update the cache, or return previously cached data.
if (steps.get_data.updateCache === true) {
console.log('updating cached stats')
// initialize the stats object
const stats = {
global: { confirmed: 0, recovered: 0, deaths: 0 },
mainlandChina: { confirmed: 0, recovered: 0, deaths: 0 },
nonMainlandChina: { confirmed: 0, recovered: 0, deaths: 0 },
}
function incrementTotals(statsObj, regionObj) {
statsObj.confirmed += parseInt(regionObj.Confirmed)
statsObj.recovered += parseInt(regionObj.Recovered)
statsObj.deaths += parseInt(regionObj.Deaths)
return statsObj
}
steps.transform_data.$return_value.forEach(function(region){
// increment global totals
stats.global = incrementTotals(stats.global, region)
if (region['Country/Region'] === 'Mainland China') {
// calculate totals for mainland china
stats.mainlandChina = incrementTotals(stats.mainlandChina, region)
} else {
// calculate totals for non-mainland china regions
stats.nonMainlandChina = incrementTotals(stats.nonMainlandChina, region)
}
})
this.$checkpoint = stats
} else {
console.log('using cached stats')
}
return this.$checkpointsteps.respond_to_client
Finally, we construct the body based on data exported and returned from previous steps, and use the moment.js npm package to provide human readable relative dates/times. We use $respond() to issue the response, set the content-type header to application/json and JSON.stringify() the data before returning it as the response body.
const moment = require('moment')
const body = {}
const lastUpdatedTimestamp = steps.get_data.$return_value.ts
const expiresTimestamp = steps.get_data.dataExpiry
+ steps.get_data.$return_value.ts
body.apiSourceCode = `https://pipedream.com/@/${steps.trigger.context.workflow_id}`
body.cache = {
lastUpdated: moment(lastUpdatedTimestamp).fromNow(),
expires: moment(expiresTimestamp).fromNow(),
lastUpdatedTimestamp,
expiresTimestamp
}
body.summaryStats = steps.summarize_data.$return_value
body.rawData = steps.transform_data.$return_value
body.dataSource = {
googleSpreadsheetId: steps.get_data.$return_value.spreadsheetId,
range: steps.get_data.$return_value.range,
googleSheetLastModified: steps.get_data.$return_value.lastModified,
dataLastPublished: moment(steps.get_data.$return_value.lastPublished).fromNow(),
dataPublishedBy: `John Hopkins University Center for Systems Science and Engineering`,
ref: `https://gisanddata.maps.arcgis.com/apps/opsdashboard/index.html#/bda7594740fd40299423467b48e9ecf6`
}
await $respond({
immediate: true,
status: 200,
headers: {
'content-type': 'application/json'
},
body: JSON.stringify(body)
})Feedback
Try out the public endpoint at https://coronavirus.m.pipedream.net/ or copy, modify and run it yourself for free on Pipedream. Please let us know if you have any feedback – you can join our public Slack at https://pipedream.com/community. And be sure to check out the great work the team at CSSE is doing.