Post-mortem on our 2/13 AWS incident


On Tuesday, 2/13, Pipedream workflow executions, tests, and deploys suffered a major outage related to an AWS Lambda incident specific to our account. This post documents what happened and what we’re doing to reduce the risk that it affects us again.
How Pipedream runs workflows
Pipedream uses AWS in almost every part of our stack. The core Pipedream service is deployed as a Kubernetes cluster on EKS. We use AWS load balancers, networks, KMS keys, S3 buckets, and more. AWS provides a highly-resilient, secure, scalable platform.
We also use AWS Lambda as a general execution environment for Pipedream workflows and event sources. Lambda has been a reliable service for Pipedream in the 4+ years we’ve been running on it. The underlying Firecracker runtime provides secure isolation between resources. It’s saved us significant engineering time letting Lambda handle this part of the stack.
AWS lets customers deploy Lambdas as .zip archives or container images. .zip functions were the only option when we launched Pipedream, and event sources still run on that model. But we recognized the value of Lambda containers as soon as they launched: .zip deployments are limited to 250 MB, but containers support images as large as 10 GB. Containers also helped us ship multi-language workflows — a single Pipedream workflow can run Node.js, Python, Go and Bash steps. All Pipedream workflows are deployed as Lambda containers today.
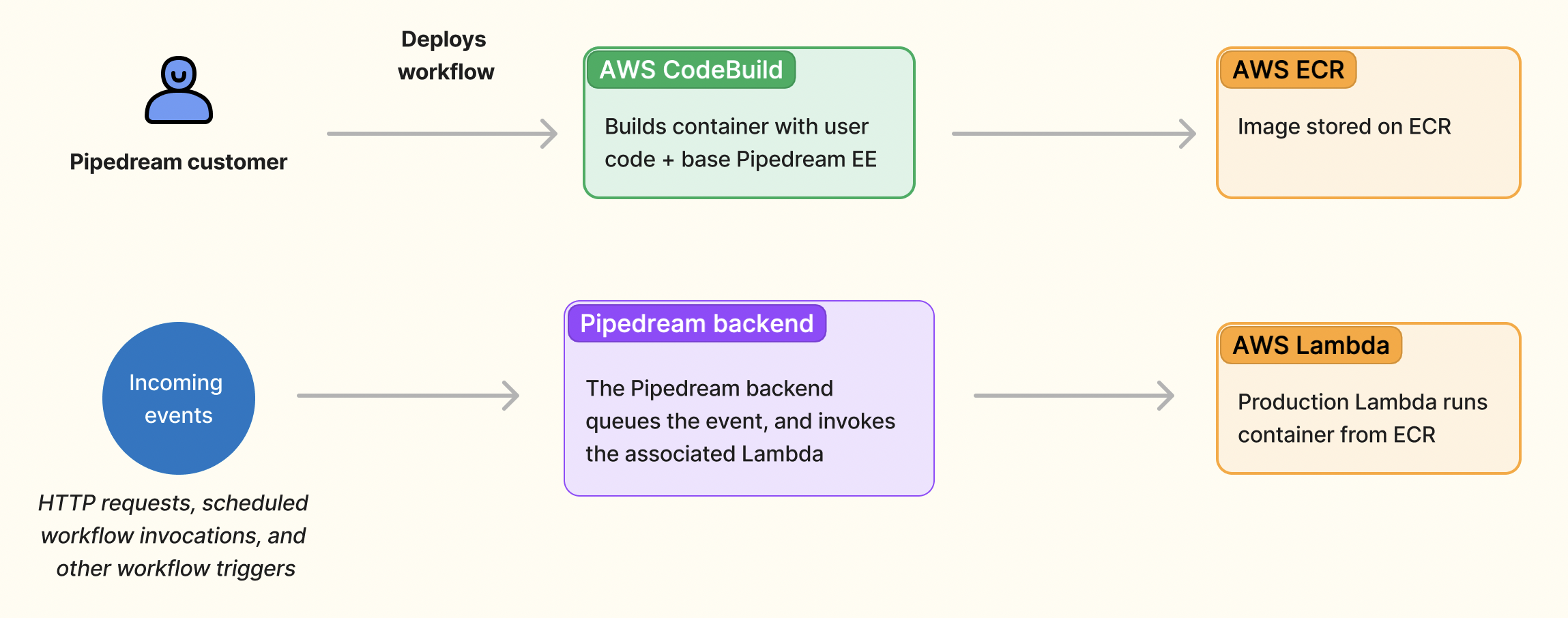
When you deploy your changes to production, we use AWS CodeBuild to build a container that combines the user’s workflow code with the base Pipedream EE. We push the final image to ECR, and deploy an associated Lambda. Since the Lambda API was down for us during the incident, we were able to build the image and push it to ECR, but failed to create the new Lambda.
Since Lambda is a core part of our stack, this incident had a big impact on our customers. Let’s cover what happened and what we’re doing to mitigate future risk.
What happened
On Tuesday 2/13, at 5:56pm PT (UTC-8), we experienced loss of access to the Lambda API in the AWS account where we run user resources. As a result, Pipedream was unable to run workflows and event sources, and users were unable to deploy and test workflows in the Pipedream UI.
At 5:58pm, the elevated 403 errors triggered an alarm in our monitoring system, and our on-call team started investigating. By 6:05pm, we were in contact with AWS Support. AWS confirmed this was related to an issue with the AWS Lambda service impacting our account, and were working to address the issue.
At 7:52pm, the Redis database we use to queue incoming events began to fill up, and caused downstream impact on other parts of our backend. Since we couldn’t process the events by running the associated workflows, we had to disable the service we use to process incoming HTTP requests. From 7:52 to 10:04pm, inbound HTTP requests would have received a 504 Gateway Timeout response. Many webhook providers (e.g. Google and Stripe) automatically re-send requests that yield 504s. If you’re calling Pipedream with your own HTTP client, we recommend you catch and retry 5XX errors, as well.
Lambda API access in our account was down from 5:56 to 9:58pm, when AWS addressed the root issue and restored our access to the Lambda API. We recovered our services, worked through the backlog of events, and closed the public incident at 11:07pm.
What we're doing to address this
These service-level disruptions are rare, but they happen. Here’s a short list of the things we’re working on to reduce our future risk:
- AWS has acknowledged the impact this had on our business. They’re delivering a root cause analysis to our team that will detail what happened and what they’re doing to address the core issues. They’ve provided direct escalation channels to help us get in touch with their team during incidents like these.
- We’re working on a way to let you run workflows in your own, private network. Not only would this give you secure access to private resources (e.g. a database that isn’t exposed to the public internet), but it would help isolate the impact of incidents that affect the general pool of resources.
- We identified a number of specific actions to improve incident response and disaster recovery for this scenario. For instance, we should be able to enqueue incoming events through the incident so that these events are processed when the system comes back online. It also took us one hour to process the backlog of events we did enqueue, and we believe we can process that backlog more efficiently in the future.
Please email dev@pipedream.com if you have any additional questions or feedback.