Archiving Slack threads to Discourse with GPT-3


We operate a public Slack community at Pipedream. Our users love the quick, synchronous chat, and the communication happens in public, so it's easy for others to find answers to common questions.
But these messages are private to Slack. You can't search Google for answers — you've got to sign up for our workspace. Plus, Slack deletes messages after 90 days on the free plan, so we lose threads quickly. But upgrading to a paid plan is costly for communities with thousands of users.
So what do we do?
Discourse as an archive
Discourse provides an open-source discussion forum. We already run our own Discourse forum for people who prefer forums to chat. All posts are public and indexed by search engines.
Discourse provides an API that will let us programmatically create new topics (the Discourse equivalent of a thread). All we need to do is convert the Slack messages to format Discourse accepts, and we'll have an archive.
For that, we use Pipedream.
Discourse Bot
When someone asks a question in Slack, we start a thread to organize communication on a specific issue. We created a Slack Bot that lets us easily archive these threads.
When we've solved a thread, we mention @Discourse Bot with the title we want for the archived Discourse post. For example, for this thread:
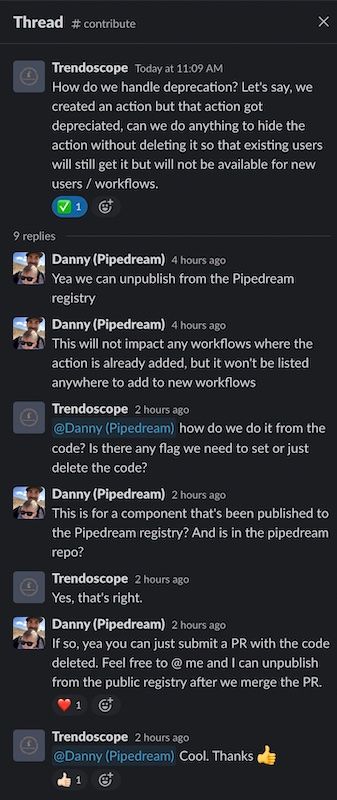
We post:
@Discourse Bot Deprecating an Action
The "at-mention" runs this Pipedream workflow, which creates a Discourse topic with the contents of the Slack thread, adding the title we sent in the message:
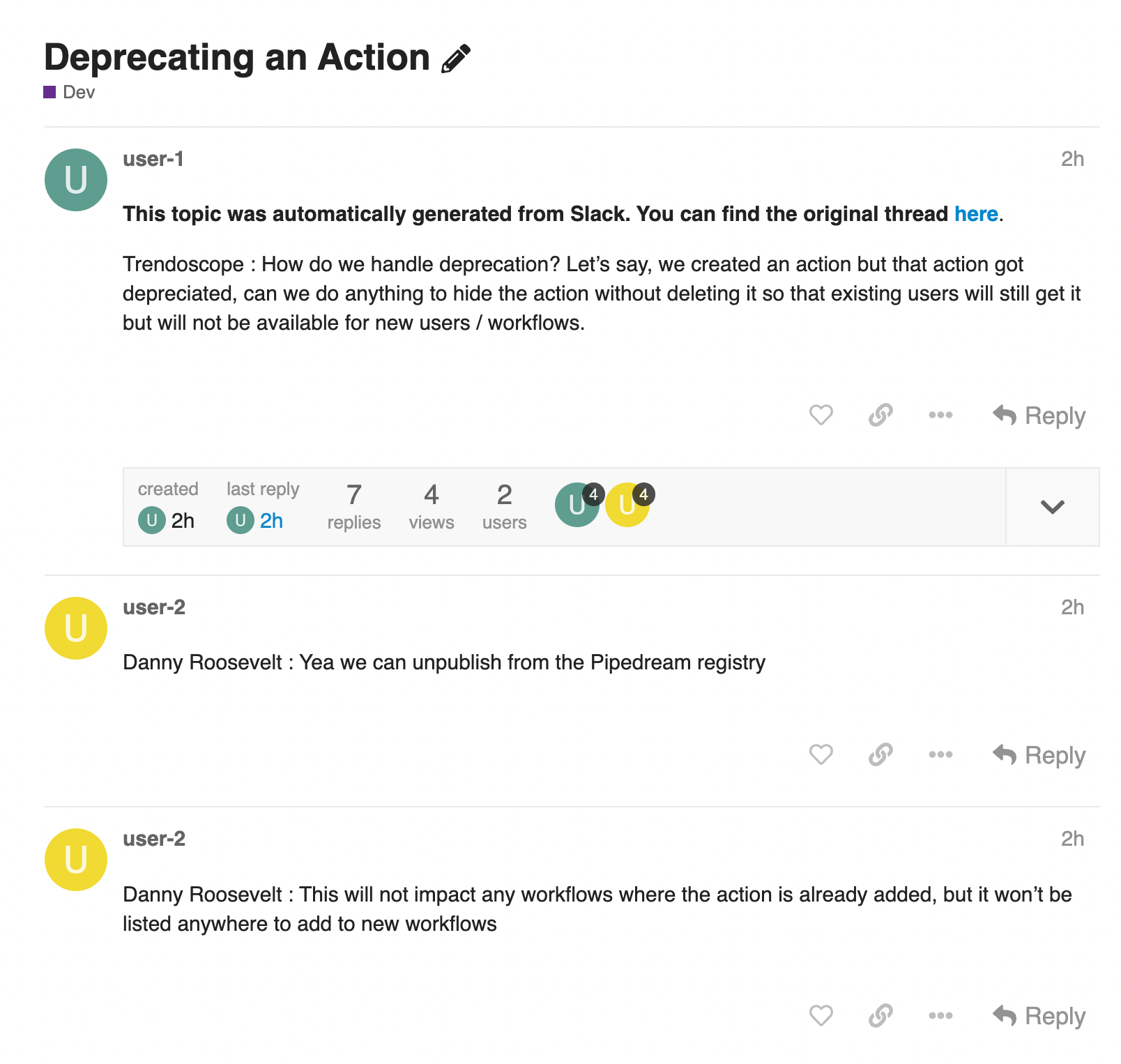
The workflow handles a ton of useful logic:
- Fetches all messages in the thread where Discourse Bot was called
- Not every Slack user has a corresponding Discourse account, so we convert Slack usernames to generic Discourse users, like
user-1anduser-2above. Not perfect, but it distinguishes messages from different Slack users on the original thread. - Converts Slack's
mrkdwnformat to standard Markdown, which Discourse uses for posts. - Creates a Discourse topic with posts for each message in the thread. We also create the topic in the right category, e.g. the
#announcementschannel archives threads to Announcements,#helpis archived to Help, etc.
Challenges with this approach
Discourse Bot was working great. But it took time to manage this process:
- It’s hard to keep track of threads that are complete. We'd set calendar reminders once a week, find all the threads we solved in the last week, and archive them to Discourse, but we inevitably missed some.
- It took time to read through some threads and figure out an appropriate summary for the title of the Discourse topic.
We let these problems simmer in the background for a few months until we thought of something that might work.
Calling threads "done"
We can safely call threads done when 7 days have passed since the last message. Any time you need to trigger something after a period of inactivity, you can use a dead man's switch:
- Set a timer, e.g. 7 days. This is your switch.
- Some service pings the switch every so often, checking in. Every time the service checks in, we reset the timer to 7 days.
- If the service stops checking in, and 7 days pass, the switch activates, triggering some action.
This is a common feature of alerting tools. Your server can ping a monitoring system every minute to tell it the server is up. If the server stops pinging, it might be down, so the monitoring system triggers an alert.
A dead man's switch can trigger any action. In this case, when 7 days have passed since the last message on a thread, we want to trigger a Pipedream workflow.
We built the switch in AWS, using DynamoDB TTLs. DynamoDB has a few properties that make it a perfect option:
- It triggers an event when an item hits its TTL, using DynamoDB streams.
- To reset the "timer" for a Slack thread, we overwrite the record for a given (
channel,thread_ts) — the key which uniquely identifies a thread — when new messages arrive on that thread. Pipedream workflow #1 handles that logic. Every public Slack message in our workspace triggers the workflow, sending them to Dynamo. - It's cheap. Assuming an average Slack thread has ten messages, it costs us roughly $0.00001538 to process one thread. That's about $15 for every one million threads, which we're unlikely to hit soon!
When threads expire, they trigger workflow #2. DynamoDB streams can't send an event to a Pipedream workflow directly, so we use a few other AWS services to get that done:
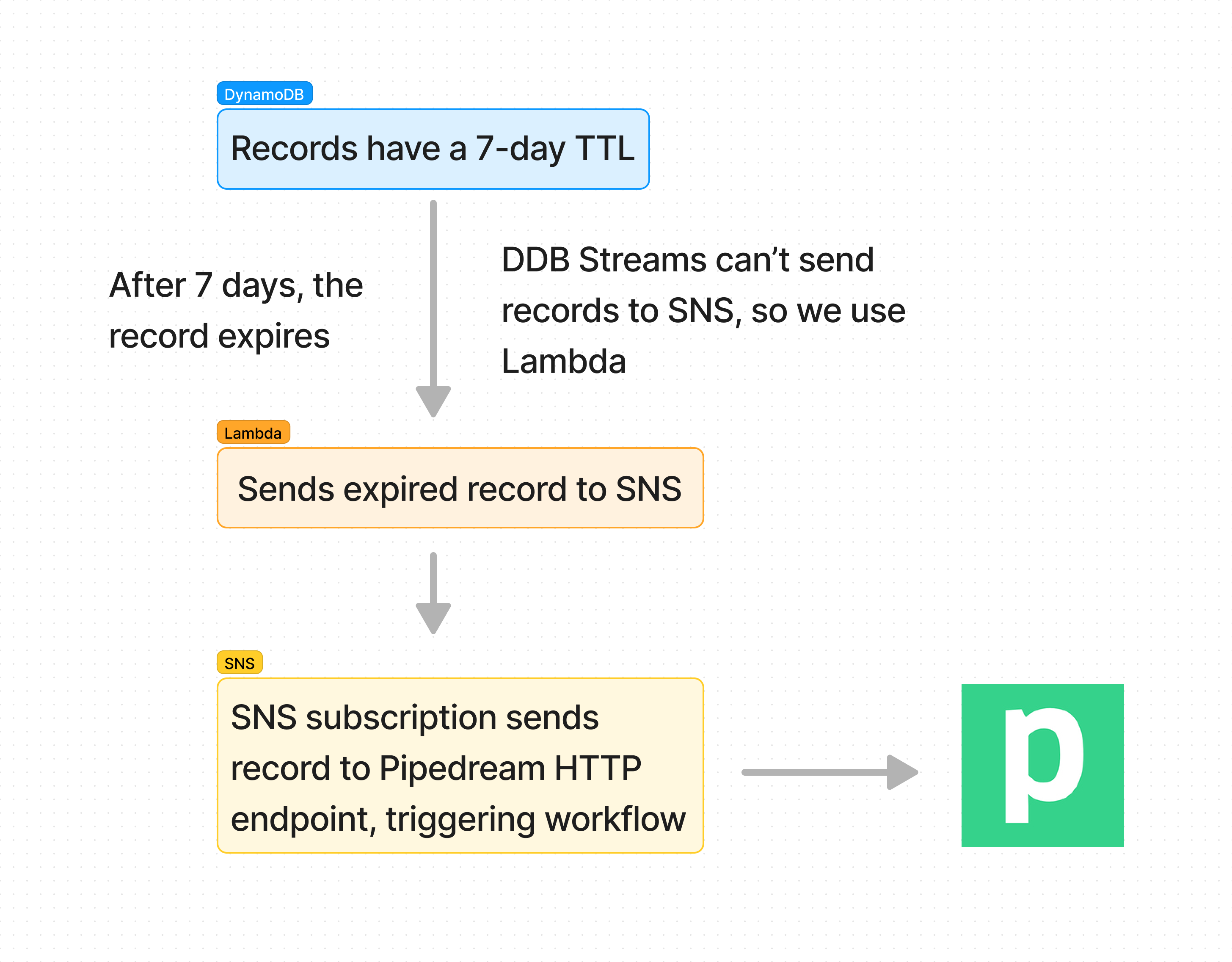
We created an AWS CDK construct that creates all the necessary resources, so you can easily make your own switch to notify a Pipedream URL when records expire:
import { Stack, StackProps } from "aws-cdk-lib";
import { Construct } from "constructs"
import { DDBDeletedItemsToHTTPS } from "@pipedream/cdk-constructs"
export class DDBDeadMansSwitch extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
new DDBDeletedItemsToHTTPS(this, 'DDBDeletedItemsToHTTPS', {
notificationURL: "https://your-endpoint.m.pipedream.net",
});
}
}The summarization process
We had also started experimenting with GPT-3 internally. GPT-3 is a language model. You give it a "prompt" — often a question, or a problem to solve — and it produces text that looks like it was written by a human.
GPT-3 can be used for a variety of tasks. For example, we can ask it a question:
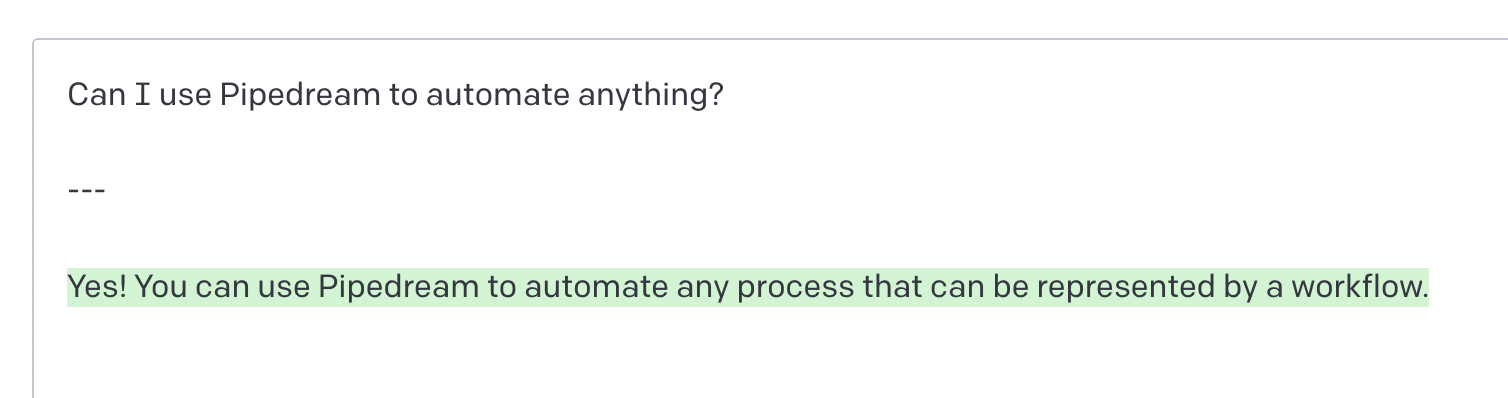
Can I use Pipedream to automate anything?
Thankfully, it replied positively 🤣:
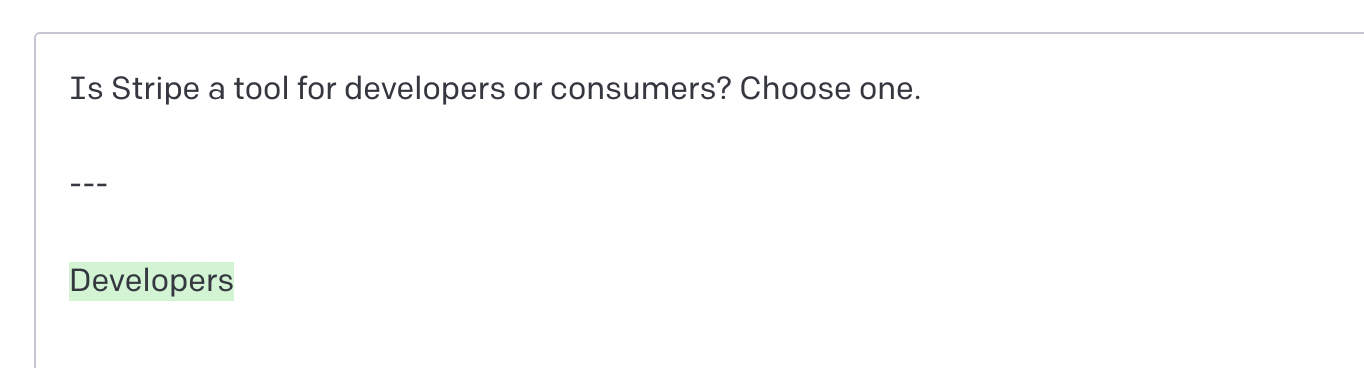
You can ask it to classify items into categories:
You can also use it to summarize text. So we thought we should ask GPT-3 to pick titles for our Discourse topics.
Completed Slack threads from Dynamo trigger workflow #2. That workflow retrieves the thread's messages from the Slack API and asks GPT-3 to summarize it. We experimented with a few prompts. This one yielded the best results:
Pick a title for the following conversation:
But the summaries can be hit or miss, depending on the thread, so we ask GPT-3 to return its best three summaries from five attempts:
{
"prompt": steps.format_prompt.$return_value,
"model": "text-davinci-002",
"max_tokens": 40,
"n": 3,
"best_of": 5,
"temperature": 0.9,
}GPT-3 model parameters
Then the workflow sends a private message to our team, asking us to choose the best one:
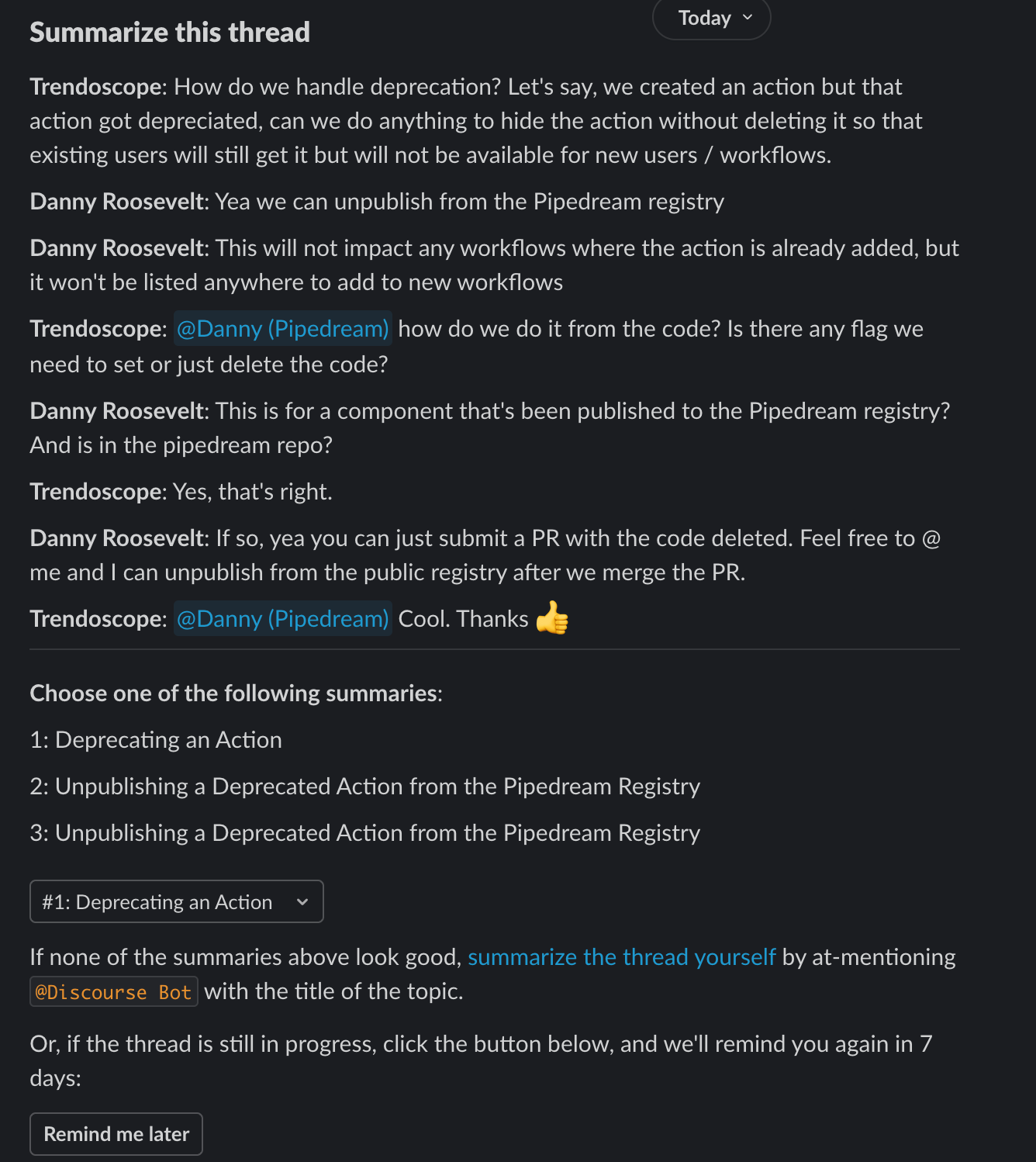
Choosing a summary triggers workflow #3: it at-mentions Discourse Bot on the original thread, which uses the original Discourse Bot workflow to archive the thread. Bots triggering bots!
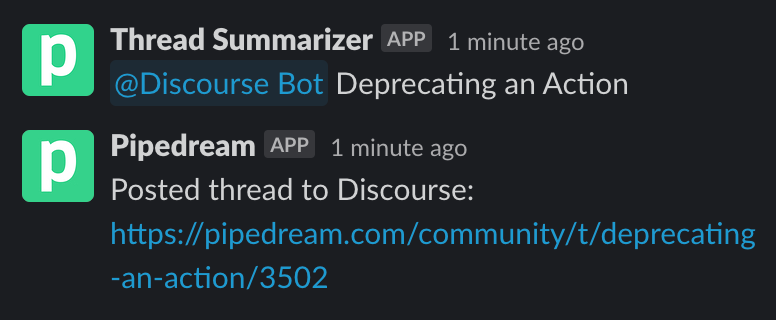
This is what the process looks like end-to-end:
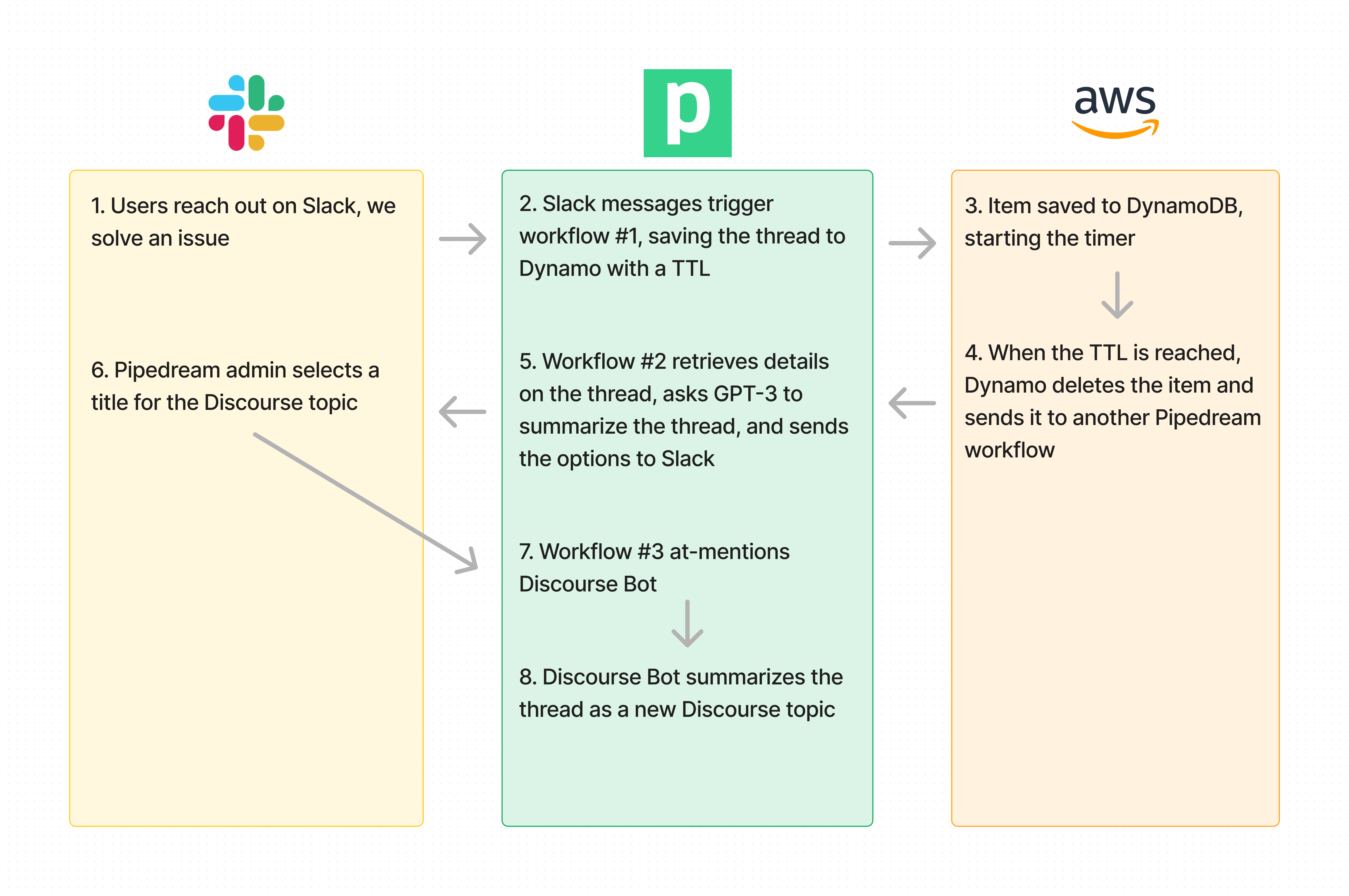
GPT-3 prices based on the specific model you use, and the number of tokens you pass it. In our case, threads average ~500 tokens each. Since we're running five summaries per thread, that works out to $.05 to summarize a single thread. Given the SEO benefit of these posts and the time this is saving us, it's a cost we can bear.
What we learned
GPT-3 is saving us time, and we're finally archiving every solved thread. But the summaries are imperfect, so the process still requires a human in the loop. For our use case, this is acceptable. We'll keep experimenting with new prompts and other methods to improve the model's accuracy.
And while using DynamoDB as a dead man's switch is cool, it's an extra dependency. Building this workflow refined our thinking on how we might add dead man's switches directly into Pipedream.
Are you using GPT-3 or Pipedream for similar use cases? Did this spur any other ideas? Tell us in our Slack community!