How to retrieve all data from an API using pagination


Transferring data between APIs and databases is a common task. On the surface the task sounds simple enough, but you'll need to consider the following when building an Extract, Transform and Load (ETL) pipeline:
- Retrieving all records from a given
GETAPI endpoint through pagination - Adhering to API rate limits
- Preventing duplicate records while retrieving and processing
- Adding fault tolerance to pick up where the import left off
- Batching records to optimize on compute usage
In this guide we'll be using HelpScout's List Conversations API as an example of processing a large amount of records. This would be helpful to extract the raw conversations text needed to train a chatbot on all past conversations with customers.
This guide complements our previous post on building your own chatbot with OpenAI and Pipedream: Build your own chat bot with OpenAI and Pipedream.
Below is an example of what this ETL workflow would look like in a Pipedream workflow, where we retrieve records from an API, transform them, and save them, while using pagination:
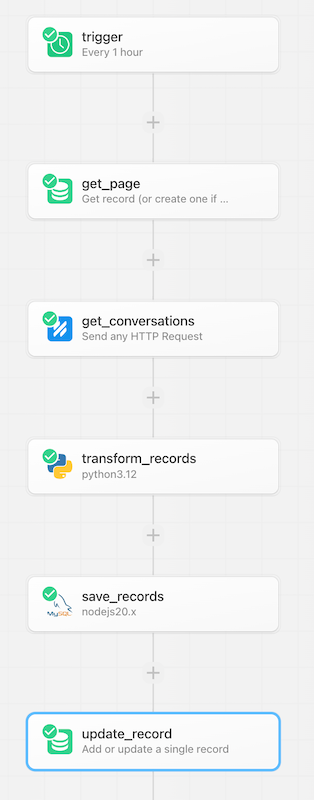
You can also accomplish pagination over APIs using a custom Source. Sources are serverless functions in Pipedream that include polling, deduplication, and triggering subscribed workflows.
But for this guide we'll use workflows, which can be built, tested and deployed without leaving the Pipedream dashboard.
You can copy this workflow to your Pipedream account with this link:
https://pipedream.com/new?h=tch_L4fRjV
Read on to learn more about about it works and best practices while paginating through APIs.
Retrieving the first page of records
First, we'll need to set up a step that will retrieve the first batch of data.
Using the Help Scout integration with Pipedream, we can quickly connect to our HelpScout account with just a few clicks.
In a new step in your workflow, search for and select the Help Scout integration, then choose the Build any Help Scout API request action:
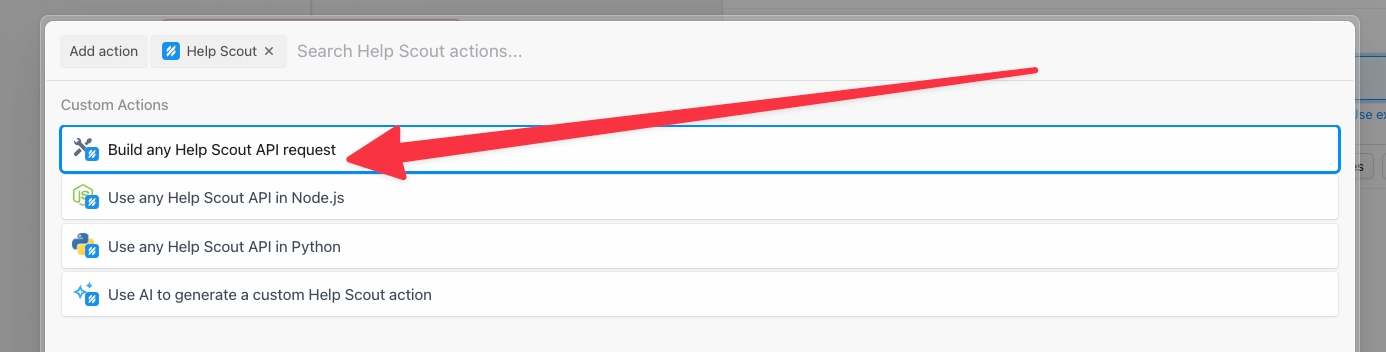
This creates an HTTP request builder with our Help Scout credentials populated once we connect our account.
Next we need to configure this API request to match the endpoint we're trying to query.
- Update the URL to match the resource you're querying.
- Click on the Params tab to open the query params passed to the request.
- Enter in the filters for this request. In my case I want all conversations, including closed ones and from a specific mailbox.
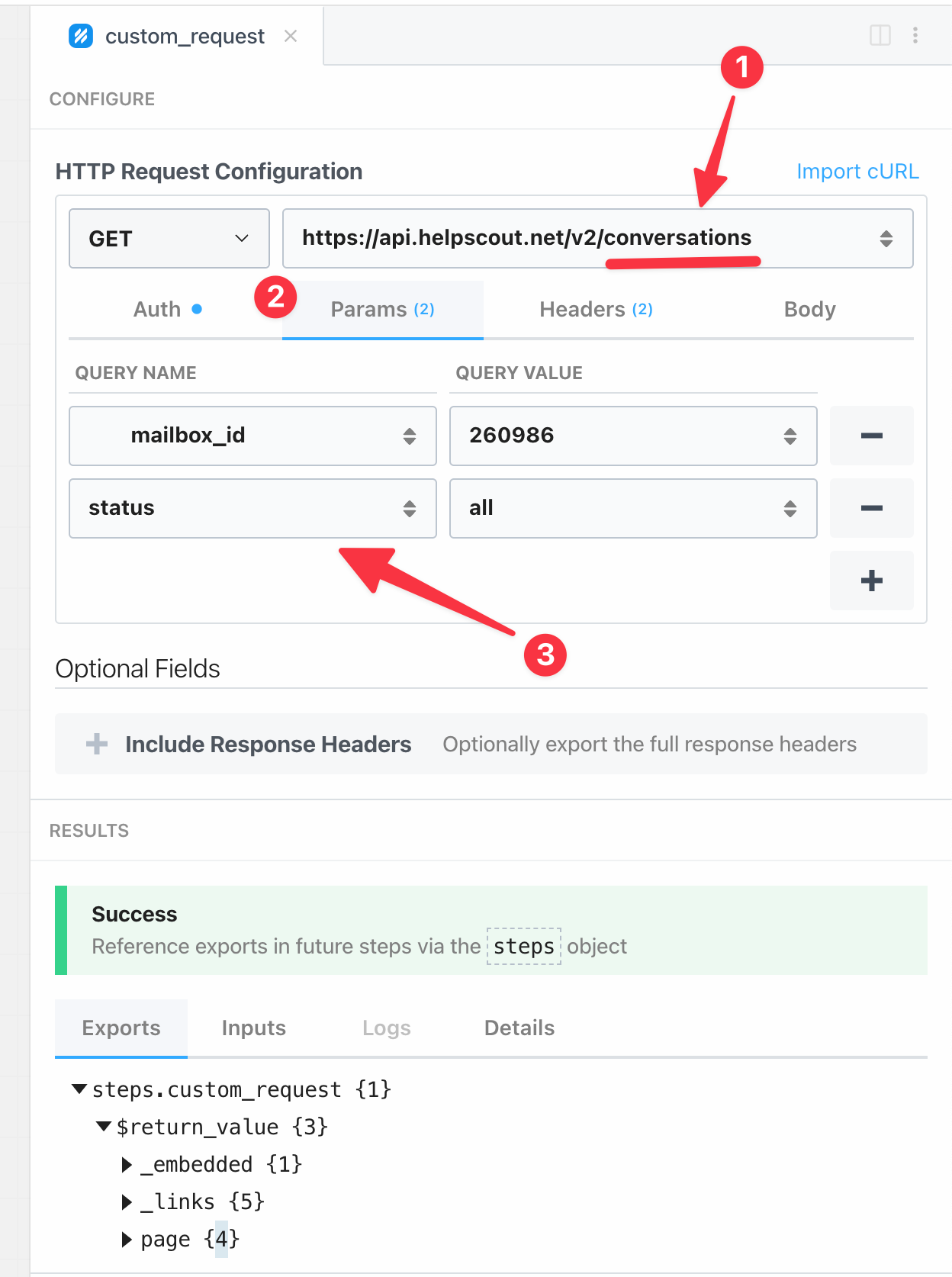
Click Test to send this API call to Help Scout, and within the response you should see the first page of results.
Great, now we have retrieved a single page, let's move onto iterating over the other pages.
Implementing pagination and fault tolerance
There are a few ways that APIs include pagination for their list or search endpoints, typically you'll see one of these two strategies:
- Page based
- Cursor based
Both strategies require storing the current page or cursor outside the workflow's execution.
Main differences between cursor and page based pagination
Page based pagination is more common, it'll allow you to define a page size and which page you'd like to view. The downside is that if your workflow encounters an error will processing a record halfway through a page, then you'll need to implement two sources of truth:
- The last successfully processed
page - The last successfully processed record by ID
This is because if you rely on the page alone, then you risk duplicating data during the Load phase of your ETL pipeline.
Whereas cursor based pagination allows you to simply to one source of truth, the last successfully retrieved and processed record.
Cursor based pagination gives a finer degree of fault tolerance without the hassle of managing two different variables during the Extract vs Transform and Load stages of your ETL pipeline.
For example, if you're iterating over a page of records from HelpScout, and want to send each individually to a CRM like HubSpot, then if the HubSpot API has an outage, your workflow will pick up on the last processed record instead of the last processed page.
How to track pages and cursors between executions
For tracking the last processed page or cursor, we recommend using a simple key/value database.
Conveniently for us, Pipedream includes a key/value store known as Data Stores.
Data Stores are first class key/value databases in Pipedream. You can utilize them to store or retrieve arbitrary JSON compatible data using pre-built actions or even in your Node.js or Python code steps.
We'll show you how to use a Data Store to store and retrieve last processed page in this sample workflow.
Retrieving the page or cursor for the next loop
Immediately after the trigger and before we perform our GET HTTP request, we'll need to retrieve the current page (or cursor) from the Data Store:
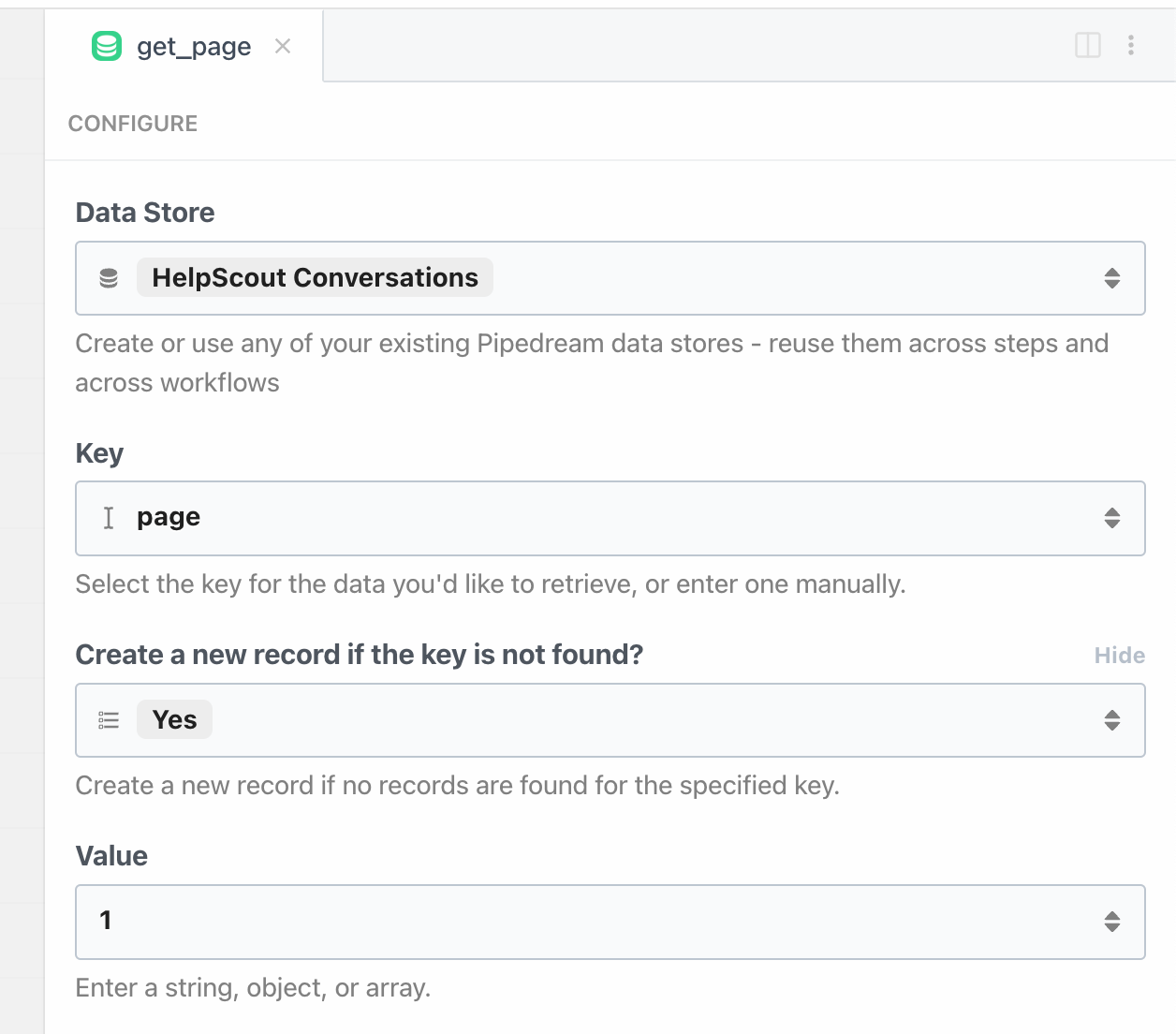
value to 1 because on the first execution of our workflow, the page key won't exist yetThis step exports the current page variable in the Data Store to our workflow at steps.get_page.$return_value.
Passing the page or cursor to the API
Now we'll need to pass the page or cursor as a param to the API call that retrieves the records.
If the API you're integrating with uses cursor based pagination, simply retrieve the stored cursor and pass it to the appropriate argument like after_cursor
HelpScout's List Conversations endpoint accepts a page query parameter, so we'll just add 1 to the last processed page to retrieve a new page:
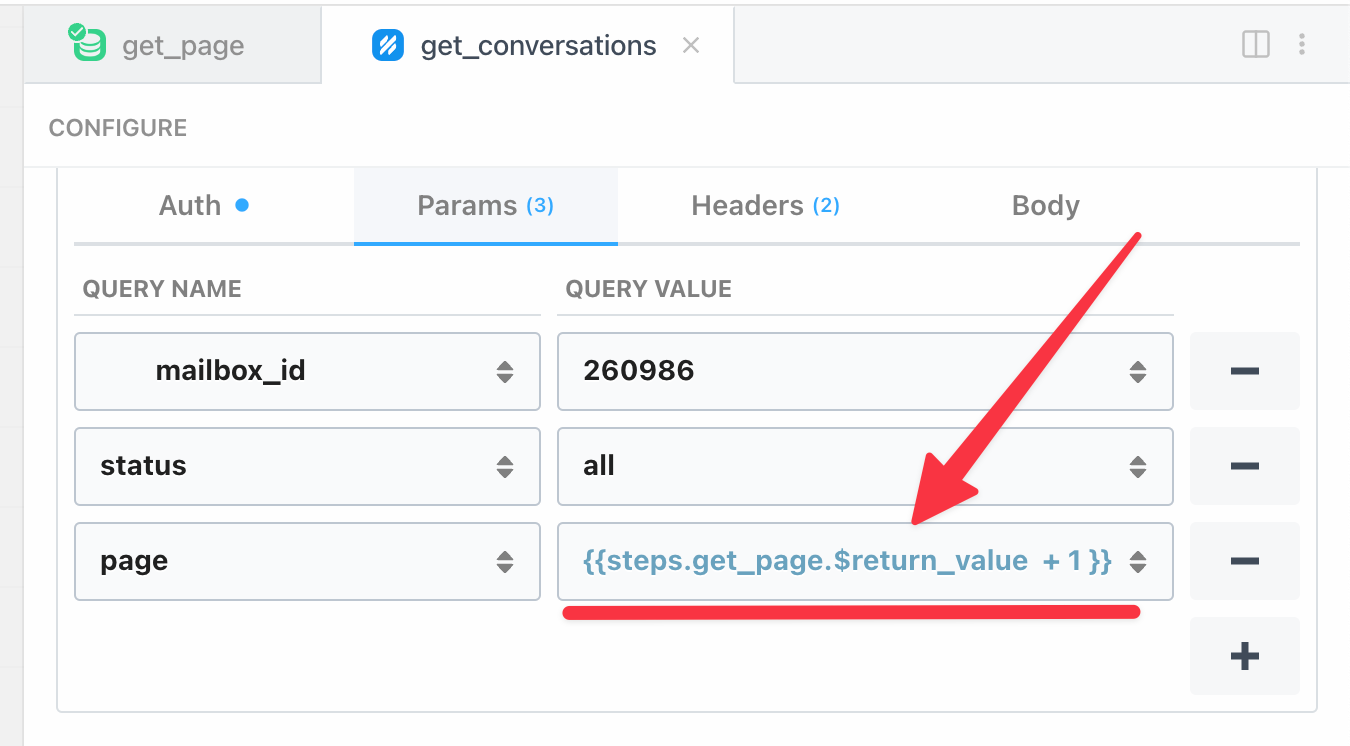
page variableMost APIs have a page parameter as a query param, which is the
Updating the page for the next execution
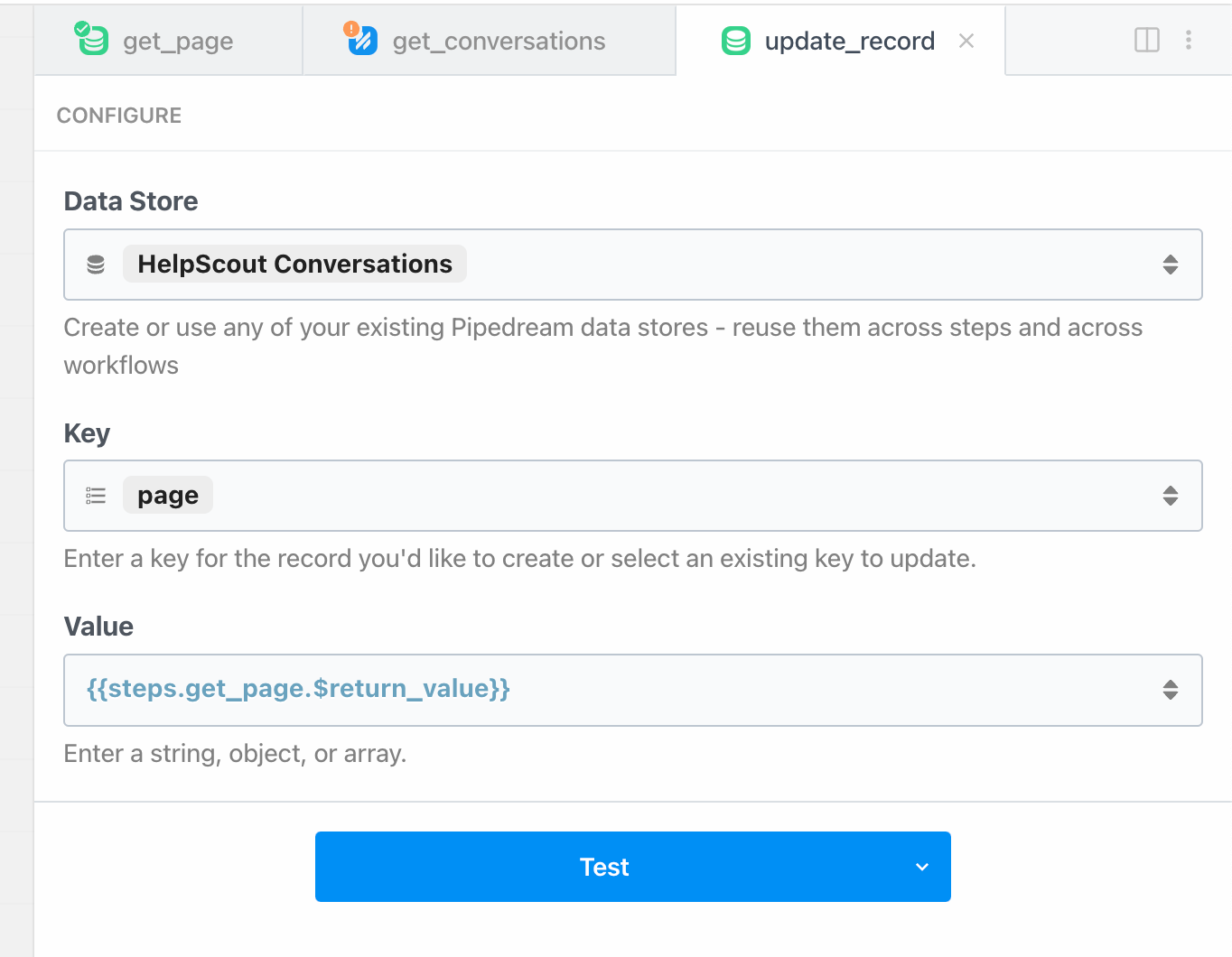
You can use the Data Stores - Update record action to store the current page number for the next workflow's execution to reference.
Please note, we highly recommend adding this step after you've performed any transformation or saved this data to another database for example.
Then after all of the operations are finished, save the page for the next iteration of the workflow.
Below is an example using the Data Store to store the last processed page number:
Constraints to keep in mind
A single Pipedream workflow execution can run for a maximum of 12.5 minutes.
But also consider that list or search API endpoints typically don't return all records in single query. You typically need to paginate through records with multiple API requests. So the 12.5 minute maximum won't be an issue.
API rate limits
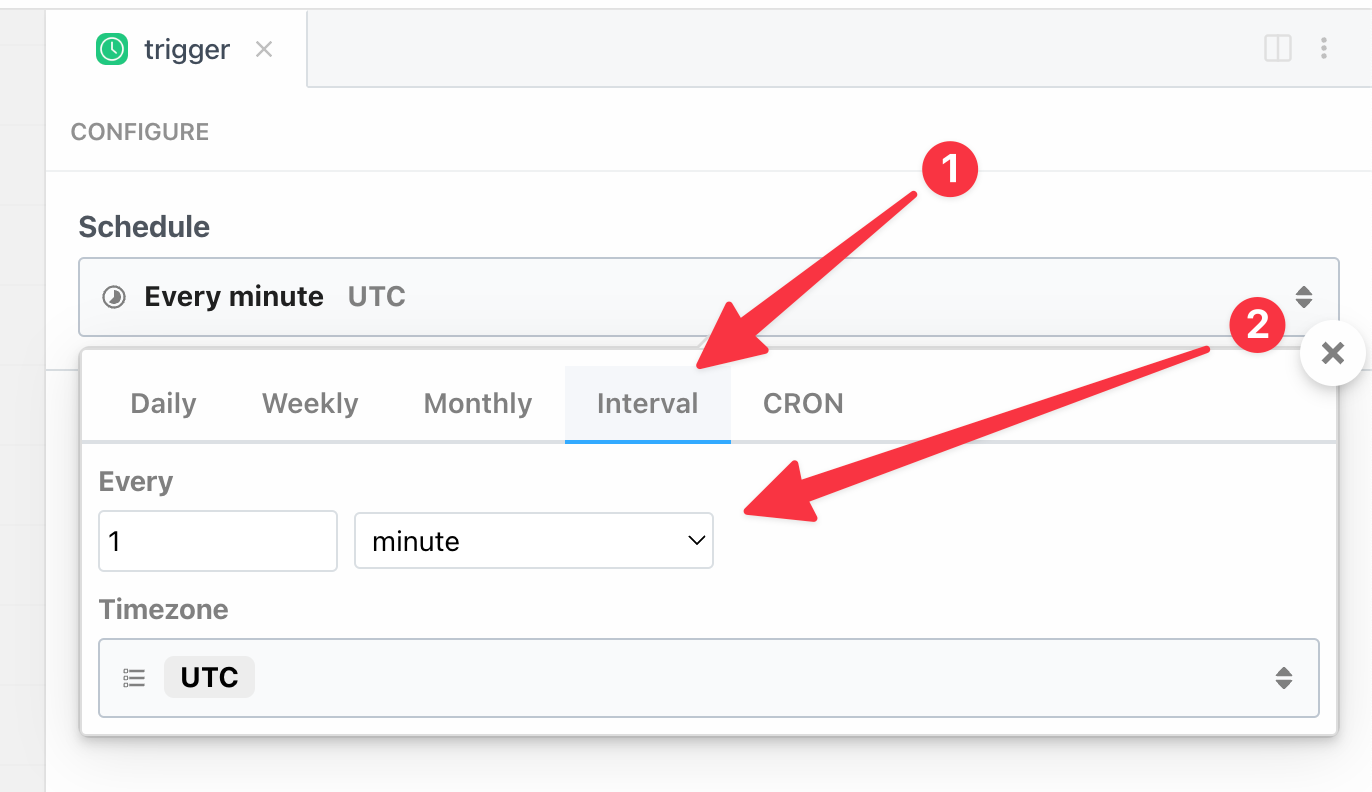
Additionally we need to make sure our workflow adheres to the 3rd party API's rate limits.
If this workflow is triggered by a schedule, you can easily control how frequently the workflow queries the 3rd party API by adjusting the schedule:
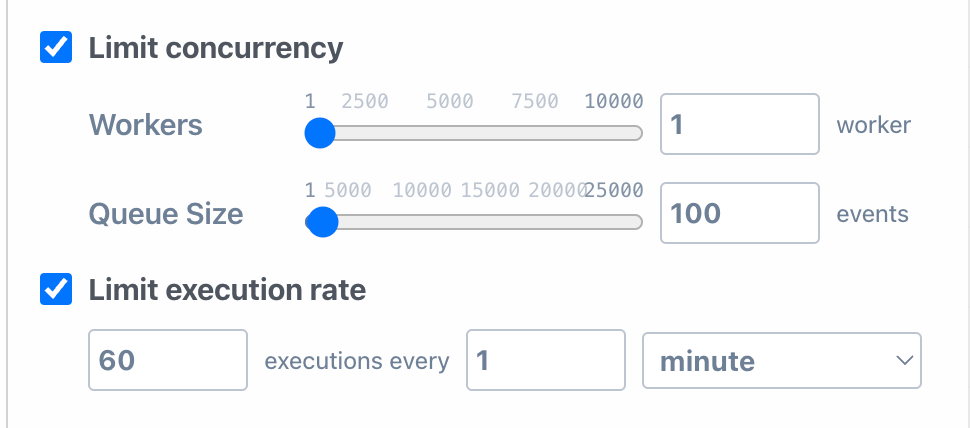
If this workflow is triggered by HTTP requests or another app, then you can use the Rate Limiting and Concurrency settings within the workflow to restrict how often the workflow runs:
Memory usage
Workflows have a finite amount of memory available. By default your workflows run at 256mb, which can be exhausted with large amounts of records in a single page.
A few ways to help prevent memory exhaustion:
- Lower the
page_sizein your query to the 3rd party API to help reduce the number of records that are stored in memory while your workflow is paginating - Increase the amount of memory allocated to your workflow
- Optimize memory by using streams to process data in chunks rather than download entire datasets, then performing another operation.
Why aren't we using a New Record trigger?
With Pipedream, you can trigger a workflow to execute when new records are added to an API. We have thousands of open source triggers for APIs that kick off your workflows. For example, the Google Sheets - New Row trigger will execute your workflow every time a new row is added to your Google Sheet.
They're great for building workflows that should process new data in real time or near real time.
However, they're not our recommended choice for ETL pipelines because:
- Credit consumption - new records cause a single execution, which will cost at least 1 credit
- Looks ahead, not behind - Pipedream triggers typically only look ahead for new events, not paginate backwards through old ones
You'll find a much higher optimization on your compute usage by batching record processing in a single run.
Try it out!
Sign up for free at Pipedream to start building your ETL pipeline using our templates or from scratch.
Our free plan doesn't require a credit card and you can subscribe, downgrade or cancel at any time.
🔨 Start building at https://pipedream.com
📣 Read our blog https://pipedream.com/blog
💬 Join our community https://pipedream.com/community