> ## Documentation Index
> Fetch the complete documentation index at: https://pipedream.com/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Pause, Resume, and Rerun a Workflow
You can use `pd.flow.suspend` and `pd.flow.rerun` to pause a workflow and resume it later.
This is useful when you want to:
* Pause a workflow until someone manually approves it
* Poll an external API until some job completes, and proceed with the workflow when it’s done
* Trigger an external API to start a job, pause the workflow, and resume it when the external API sends an HTTP callback
We’ll cover all of these examples below.
## `pd.flow.suspend`
Use `pd.flow.suspend` when you want to pause a workflow and proceed with the remaining steps only when manually approved or cancelled.
For example, you can suspend a workflow and send yourself a link to manually resume or cancel the rest of the workflow:
```python theme={null}
def handler(pd: 'pipedream'):
urls = pd.flow.suspend()
pd.send.email(
subject="Please approve this important workflow",
text=f"Click here to approve the workflow: ${urls["resume_url"]}, and cancel here: ${urls["cancel_url"]}"
)
# Pipedream suspends your workflow at the end of the step
```
You’ll receive an email like this:
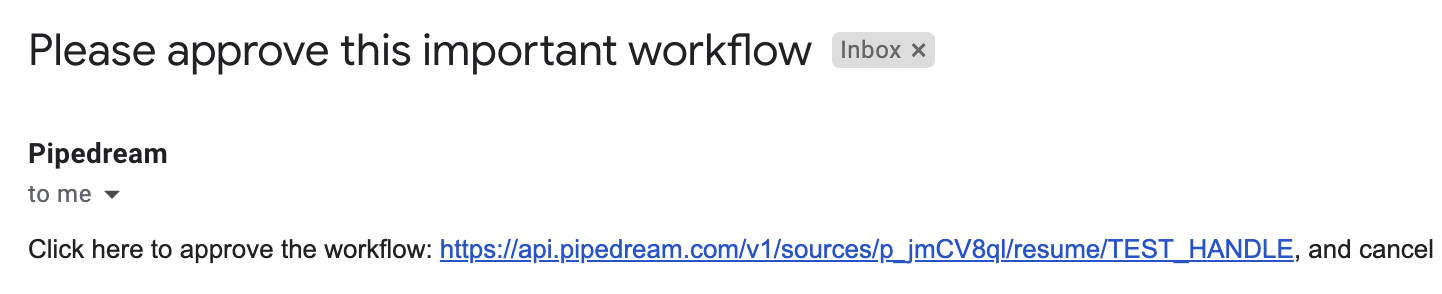 And can resume or cancel the rest of the workflow by clicking on the appropriate link.
### `resume_url` and `cancel_url`
In general, calling `pd.flow.suspend` returns a `cancel_url` and `resume_url` that lets you cancel or resume paused executions. Since Pipedream pauses your workflow at the *end* of the step, you can pass these URLs to any external service before the workflow pauses. If that service accepts a callback URL, it can trigger the `resume_url` when its work is complete.
These URLs are specific to a single execution of your workflow. While the workflow is paused, you can load these in your browser or send any HTTP request to them:
* Sending an HTTP request to the `cancel_url` will cancel that execution
* Sending an HTTP request to the `resume_url` will resume that execution
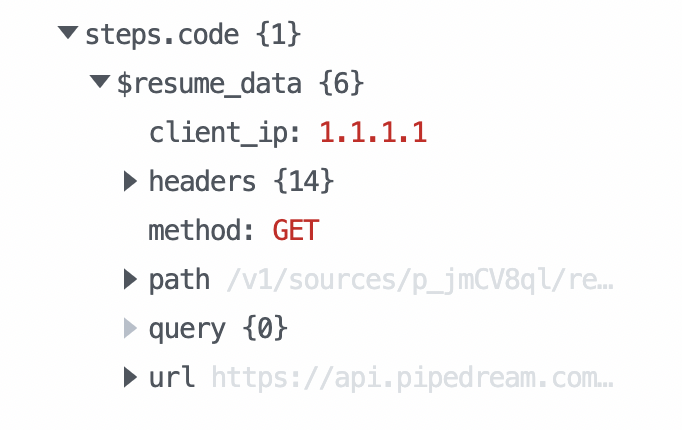
If you resume a workflow, any data sent in the HTTP request is passed to the workflow and returned in the `$resume_data` [step export](/workflows/#step-exports) of the suspended step. For example, if you call `pd.flow.suspend` within a step named `code`, the `$resume_data` export should contain the data sent in the `resume_url` request:
And can resume or cancel the rest of the workflow by clicking on the appropriate link.
### `resume_url` and `cancel_url`
In general, calling `pd.flow.suspend` returns a `cancel_url` and `resume_url` that lets you cancel or resume paused executions. Since Pipedream pauses your workflow at the *end* of the step, you can pass these URLs to any external service before the workflow pauses. If that service accepts a callback URL, it can trigger the `resume_url` when its work is complete.
These URLs are specific to a single execution of your workflow. While the workflow is paused, you can load these in your browser or send any HTTP request to them:
* Sending an HTTP request to the `cancel_url` will cancel that execution
* Sending an HTTP request to the `resume_url` will resume that execution
If you resume a workflow, any data sent in the HTTP request is passed to the workflow and returned in the `$resume_data` [step export](/workflows/#step-exports) of the suspended step. For example, if you call `pd.flow.suspend` within a step named `code`, the `$resume_data` export should contain the data sent in the `resume_url` request:
 ### Default timeout of 24 hours
By default, `pd.flow.suspend` will automatically cancel the workflow after 24 hours. You can set your own timeout (in milliseconds) as the first argument:
```python theme={null}
def handler(pd: 'pipedream'):
# 7 days
TIMEOUT = 1000 * 60 * 60 * 24 * 7
pd.flow.suspend(TIMEOUT)
```
## `pd.flow.rerun`
Use `pd.flow.rerun` when you want to run a specific step of a workflow multiple times. This is useful when you need to start a job in an external API and poll for its completion, or have the service call back to the step and let you process the HTTP request within the step.
### Polling for the status of an external job
Sometimes you need to poll for the status of an external job until it completes. `pd.flow.rerun` lets you rerun a specific step multiple times:
```python theme={null}
import requests
def handler(pd: 'pipedream'):
MAX_RETRIES = 3
# 10 seconds
DELAY = 1000 * 10
run = pd.context['run']
print(pd.context)
# pd.context.run.runs starts at 1 and increments when the step is rerun
if run['runs'] == 1:
# pd.flow.rerun(delay, context (discussed below), max retries)
pd.flow.rerun(DELAY, None, MAX_RETRIES)
elif run['runs'] == MAX_RETRIES + 1:
raise Exception("Max retries exceeded")
else:
# Poll external API for status
response = requests.get("https://example.com/status")
# If we're done, continue with the rest of the workflow
if response.json().status == "DONE":
return response.json()
# Else retry later
pd.flow.rerun(DELAY, None, MAX_RETRIES)
```
`pd.flow.rerun` accepts the following arguments:
```python theme={null}
pd.flow.rerun(
delay, # The number of milliseconds until the step will be rerun
context, # JSON-serializable data you need to pass between runs
maxRetries, # The total number of times the step will rerun. Defaults to 10
)
```
### Accept an HTTP callback from an external service
When you trigger a job in an external service, and that service can send back data in an HTTP callback to Pipedream, you can process that data within the same step using `pd.flow.retry`:
```python theme={null}
import requests
def handler(pd: 'pipedream'):
TIMEOUT = 86400 * 1000
run = pd.context['run']
# pd.context['run']['runs'] starts at 1 and increments when the step is rerun
if run['runs'] == 1:
links = pd.flow.rerun(TIMEOUT, None, 1)
# links contains a dictionary with two entries: resume_url and cancel_url
# Send resume_url to external service
await request.post("your callback URL", json=links)
# When the external service calls back into the resume_url, you have access to
# the callback data within pd.context.run['callback_request']
elif 'callback_request' in run:
return run['callback_request']
```
### Passing `context` to `pd.flow.rerun`
Within a Python code step, `pd.context.run.context` contains the `context` passed from the prior call to `rerun`. This lets you pass data from one run to another. For example, if you call:
```python theme={null}
pd.flow.rerun(1000, { "hello": "world" })
```
`pd.context.run.context` will contain:
### Default timeout of 24 hours
By default, `pd.flow.suspend` will automatically cancel the workflow after 24 hours. You can set your own timeout (in milliseconds) as the first argument:
```python theme={null}
def handler(pd: 'pipedream'):
# 7 days
TIMEOUT = 1000 * 60 * 60 * 24 * 7
pd.flow.suspend(TIMEOUT)
```
## `pd.flow.rerun`
Use `pd.flow.rerun` when you want to run a specific step of a workflow multiple times. This is useful when you need to start a job in an external API and poll for its completion, or have the service call back to the step and let you process the HTTP request within the step.
### Polling for the status of an external job
Sometimes you need to poll for the status of an external job until it completes. `pd.flow.rerun` lets you rerun a specific step multiple times:
```python theme={null}
import requests
def handler(pd: 'pipedream'):
MAX_RETRIES = 3
# 10 seconds
DELAY = 1000 * 10
run = pd.context['run']
print(pd.context)
# pd.context.run.runs starts at 1 and increments when the step is rerun
if run['runs'] == 1:
# pd.flow.rerun(delay, context (discussed below), max retries)
pd.flow.rerun(DELAY, None, MAX_RETRIES)
elif run['runs'] == MAX_RETRIES + 1:
raise Exception("Max retries exceeded")
else:
# Poll external API for status
response = requests.get("https://example.com/status")
# If we're done, continue with the rest of the workflow
if response.json().status == "DONE":
return response.json()
# Else retry later
pd.flow.rerun(DELAY, None, MAX_RETRIES)
```
`pd.flow.rerun` accepts the following arguments:
```python theme={null}
pd.flow.rerun(
delay, # The number of milliseconds until the step will be rerun
context, # JSON-serializable data you need to pass between runs
maxRetries, # The total number of times the step will rerun. Defaults to 10
)
```
### Accept an HTTP callback from an external service
When you trigger a job in an external service, and that service can send back data in an HTTP callback to Pipedream, you can process that data within the same step using `pd.flow.retry`:
```python theme={null}
import requests
def handler(pd: 'pipedream'):
TIMEOUT = 86400 * 1000
run = pd.context['run']
# pd.context['run']['runs'] starts at 1 and increments when the step is rerun
if run['runs'] == 1:
links = pd.flow.rerun(TIMEOUT, None, 1)
# links contains a dictionary with two entries: resume_url and cancel_url
# Send resume_url to external service
await request.post("your callback URL", json=links)
# When the external service calls back into the resume_url, you have access to
# the callback data within pd.context.run['callback_request']
elif 'callback_request' in run:
return run['callback_request']
```
### Passing `context` to `pd.flow.rerun`
Within a Python code step, `pd.context.run.context` contains the `context` passed from the prior call to `rerun`. This lets you pass data from one run to another. For example, if you call:
```python theme={null}
pd.flow.rerun(1000, { "hello": "world" })
```
`pd.context.run.context` will contain:
 ### `maxRetries`
By default, `maxRetries` is **10**.
When you exceed `maxRetries`, the workflow proceeds to the next step. If you need to handle this case with an exception, `raise` an Exception from the step:
```python theme={null}
def handler(pd: 'pipedream'):
MAX_RETRIES = 3
run = pd.context['run']
if run['runs'] == 1:
pd.flow.rerun(1000, None, MAX_RETRIES)
else if (run['runs'] == MAX_RETRIES + 1):
raise Exception("Max retries exceeded")
```
## Behavior when testing
When you’re building a workflow and test a step with `pd.flow.suspend` or `pd.flow.rerun`, it will not suspend the workflow, and you’ll see a message like the following:
> Workflow execution canceled — this may be due to `pd.flow.suspend()` usage (not supported in test)
These functions will only suspend and resume when run in production.
## Credits usage when using `pd.flow.suspend` / `pd.flow.rerun`
You are not charged for the time your workflow is suspended during a `pd.flow.suspend` or `pd.flow.rerun`. Only when workflows are resumed will compute time count toward [credit usage](/pricing/#credits-and-billing).
When a suspended workflow reawakens, it will reset the credit counter.
Each rerun or reawakening from a suspension will count as a new fresh credit.
### `maxRetries`
By default, `maxRetries` is **10**.
When you exceed `maxRetries`, the workflow proceeds to the next step. If you need to handle this case with an exception, `raise` an Exception from the step:
```python theme={null}
def handler(pd: 'pipedream'):
MAX_RETRIES = 3
run = pd.context['run']
if run['runs'] == 1:
pd.flow.rerun(1000, None, MAX_RETRIES)
else if (run['runs'] == MAX_RETRIES + 1):
raise Exception("Max retries exceeded")
```
## Behavior when testing
When you’re building a workflow and test a step with `pd.flow.suspend` or `pd.flow.rerun`, it will not suspend the workflow, and you’ll see a message like the following:
> Workflow execution canceled — this may be due to `pd.flow.suspend()` usage (not supported in test)
These functions will only suspend and resume when run in production.
## Credits usage when using `pd.flow.suspend` / `pd.flow.rerun`
You are not charged for the time your workflow is suspended during a `pd.flow.suspend` or `pd.flow.rerun`. Only when workflows are resumed will compute time count toward [credit usage](/pricing/#credits-and-billing).
When a suspended workflow reawakens, it will reset the credit counter.
Each rerun or reawakening from a suspension will count as a new fresh credit.